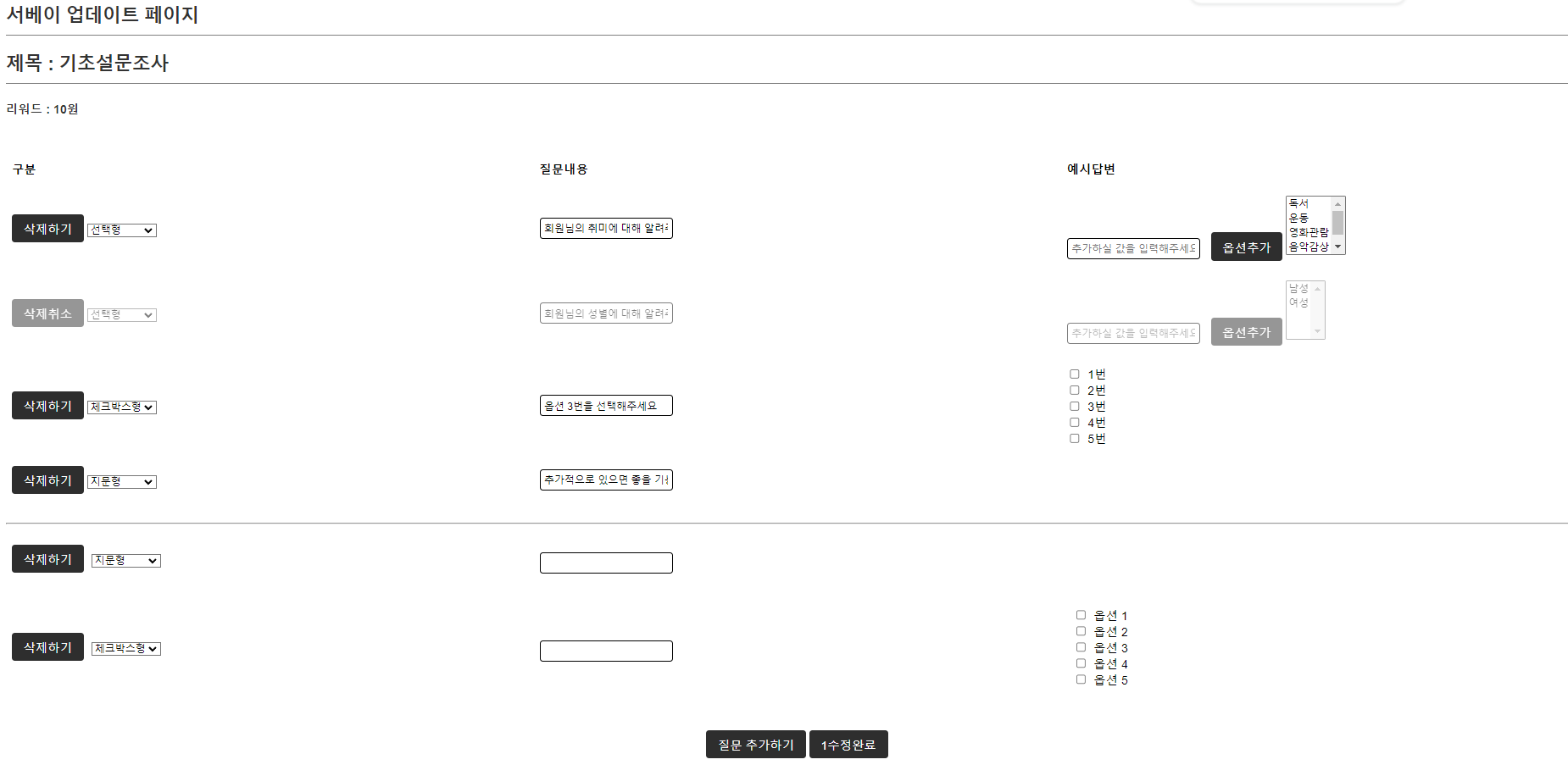
3. putty 설치 파일 위치에서 puttygen클릭, AWS에서 받아온 키파일 로드 (pem -> ppk 변환하기)
(정상적으로 됬을경우 해당 alert 출력)
4.현 상태에서 save private key 클릭하여 저장
5. putty 실행하여 HostName은 AWS의 IPv4 복붙
6. putty 좌측 카테고리의 Connection- SSH - Auth - Credential의 Private Key File에 아까 puttygen으로 생성한 ppk파일 등록 후 오픈 (모든 설정을 마치고 Session의 Saved Sessions탭의 save,load를 누르면 현재 설정을 저장 및 로드가 가능하다.)
7. open을 눌렀을시 해당 창이 나타나며 ubuntu를 입력했을때 문제가 ㅇ벗다면 AWS의 ip가 나타나며 연결완료
@RequestMapping은 특정 HTTP 요청(예: GET, POST, PUT, DELETE 등)을 컨트롤러의 메소드에 매핑합니다. 이를 통해 해당 요청이 들어왔을 때 어떤 메소드가 처리할지 정의할 수 있습니다.
즉, 우리가 front에서 페이지를 통해 무언가의 작업 (form 제출, 버튼 클릭 등)을 실행했고 이를 Back의 어디서 제어를 담당할지 정해야 하는데 이부분을 정해주는게 해당 어노테이션이다.
URL 패턴(value="/users"), HTTP 메소드(get,put,delete,post), 헤더, 매개변수(MemberVO membervo) 등을 지정할 수 있습니다.
@RequestMapping("/users")
public String getUsers() {
// 사용자 목록을 반환하는 로직
}
@RequestMapping(value = "/users", method = RequestMethod.GET)
public String getUsers(MemberVO membervo) {
// 사용자 목록을 반환하는 로직
}
@PathVariable
@PathVariable은 URL 경로의 일부를 변수로 추출하여 파라미터로 사용이 가능하도록 해준다.
URL패턴인 /users/{userId} 에서 {userId} 부분을 추출하여 메소드에 전달, 이것을 파라미터로 사용이 가능하다
즉, 하단의 예시코드는 gifticonDelete/{gifticon_id}으로 요청이 들어왔을때 gifticon_id을 활용하는 형식이다.
URL의 예시 :/users/123
@RequestMapping(value = "/users/{userId}", method = RequestMethod.GET)
public String getUserById(@PathVariable("userId") Long userId) {
// userId = 123
}
//예시
@RequestMapping("/gifticonDelete/{gifticon_id}")
public String gifticonDelete(@PathVariable("gifticon_id") int gifticon_id) {
gifticonService.gifticonDelete(gifticon_id);
return "redirect:/shop";
}
@RequestParam
사용자가 전달하는 값을 매개변수로 1:1 매핑이 가능하도록 해주는 어노테이션.
한번에 여러개의 값의 사용해야 할땐 ModelAttribute이 더 낫다. -> 만일 RequestParam이 1개가 아닌 여러개일때 나중에 이를 재사용하기 힘들어진다.
//URL의 예시 : /users?id=admin
@RequestMapping("/users")
public String exgetUsers(@RequestParam("id") String userId) {
// userId = admin
//URL에선 id로 나타나지만 다른형식으로 변환해서 사용하고 싶을때 "("기본이름") 원하는이름"의 형태이다.
}
// URL예시 : /users?id=123&name=John&email=john@example.com&phone=010-1234-5678
@RequestMapping("/users")
public String exgetUsers2(@RequestParam String id, @RequestParam String name,
@RequestParam String email,
@RequestParam String phone) {
// id = 123
// name = John
// email = john@example.com
// phone = 010-1234-5678
}
@ModelAttribute
전체 데이터를 받아 객체로 매핑할 때 사용한다.
한번에 여러 데이터가 오가는 폼에서 자주 사용되는 경우가 많다.
해당 어노테이션은 스프링에서 생략하여도 자동적으로 붙
@PostMapping("/register")
public String register(@ModelAttribute MemberVO membervo) {
// membervo 객체를 사용하는 로직
}
public String register(MemberVO membervo) {
// 이렇게 해도 무방하다
}
ResponseEntity
HTTP 응답의 본문, 상태 코드, 헤더 등을 전체적으로 제어할 수 있게 해주는 클래스
void를 사용한 ajax의 경우 문제없이 작동하더라도 return할게 없을때 error가 나타나는데 해당 방식을 활용하면 끝남과 동시에 http 코드도 함께 전달이 가능해져서 error가 나타나지 않게된다.
@GetMapping("/user/{id}")
public ResponseEntity<User> getUserById(@PathVariable("id") Long userId) {
User user = MemberDAO.getmember(userId);
return ResponseEntity.ok(user); // 200 OK 응답과 함께 유저 반환
}
HttpServletRequest
front에서 back으로 데이터를 보냈을때 보내지는 데이터(헤더, 쿠키, 세션 등)가 캡슐화가 되어 전달된다.
@GetMapping("/example")
public String handleRequest(HttpServletRequest request) {
String clientIP = request.getRemoteAddr(); // 클라이언트 IP 주소 가져오기
// HttpServletRequest를 사용한 다른 로직
return "viewName";
}
AJAX를 통한 크롤링이 늘어나면서 SOP를 따질경우 제약이 너무 많아지기에 CORS정책이 나오게 되었다.
개발자도구 - network 탭에서 Access-Control-Allow-Origin란 헤더가 없을경우 다음과 같은 에러가 나타나게된다.
//크로스도메인 에러
XMLHttpRequest cannot load http://www.abc.co.kr.
No 'Access-Control-Allow-Origin' header is present on the requested resource.
Origin 'http://cvb.abc.co.kr' is therefore not allowed access.
프로토콜 - 연결,통신 데이터 전송을 제어하는 일련의 규칙 및 표준 (http, https...)
스킴 (Scheme)- URL체계 최상위 레벨로 특정 프로토콜의 이름
http: 일반적인 웹 페이지에 접근하기 위한 HTTP 프로토콜.
https: 보안 웹 페이지에 접근하기 위한 HTTP Secure 프로토콜.
ftp: 파일 전송 프로토콜(FTP)을 사용하여 파일을 전송하거나 다운로드할 때 사용.
mailto: 이메일 주소를 지정하고 이메일 클라이언트를 열 때 사용.
크로스 도메인 이슈(CORS, Cross Origin Resource Sharing)
HTTP헤더 기반 매커니즘으로 동일 출처 이외의 다른출처도 접근할수 있도록 하는 기능 -> 다른 사이트의 코드를 허가없이 도용하는걸 방지하기 위함
만일 CORS정책을 지키지 않은상태로 다른 출처가 리소스의 로드를 요청할경우 SOP에 의해 거부, 리소스가 차단
서버가 실제 요청을 허용하는지 확인을 위해 브라우저가 원본간 리소스를 호스팅하는 서버에 "실행전" 요청 매커니즘에 의존한다.
브라우저에서 두번쨰 요청 도메인이 처음 요청을 받고 응답한 사이트의 도메인에 포함된 URL이 아닐경우 에러
Simple request, Pre-flighted request 2종류로 나뉜다.
Simple request (간단한 요청)
pre-flighted 없이 GET,HAED,POST중 1가지 방식이며 POST는 content-type이 하단과 같은경우에만 허용된다.
application/x-www-form-unlencoded,
multipart/form-data
text/plain
클라이언트가 요청을 보낼경우 브라우저는 CORS에 대한 헤더를 추가하여 서버에 전달 -> 서버가 헤더 확인후 Origin(출처)값이 허용된다면 요청 헤더의 Access-Control-Allow-Origin를 Origin 값으로 설정한뒤 브라우저에 보낸다 -> 브라우저는 Access-Control-Allow-Origin가 탭의 출처와 일치하는지 확인한다 (와일드카드도 적용된다)
Preflighted Request (사전 요청)
복잡한 요청을 보내기전 브라우저가OPTIONS 메서드를 사용하여 서버가 해당 요청을 수용할 수 있는지 확인하는 것입니다.
요청을 보낸다 -> 서버는 Access-Control-Allow-Origing헤더를 참고하여 SOP를 검증 -> 브라우저는 CORS 요청을 보낸다 -> 해당 요청이 허용된경우 실제 요청 처리
JSON방식으로 데이터를 가져올떈 SOP에 영향을 받지만 JS, CSS파일은 SOP에 영향을 받지 않으므로 JS파일 내부에서 JSON형식으로 파싱해 사용가능
브라우저에 화면이 출력되는건 알았지만 이게 서버, 클라이언트 어디서 작업을 하는지 궁금했고 어디서 사용하는게 더욱 효율적인지 궁금하여 포스팅한다.
렌더링 -> 서버로부터 요청받은 내용을 브라우저에 표시해주는것
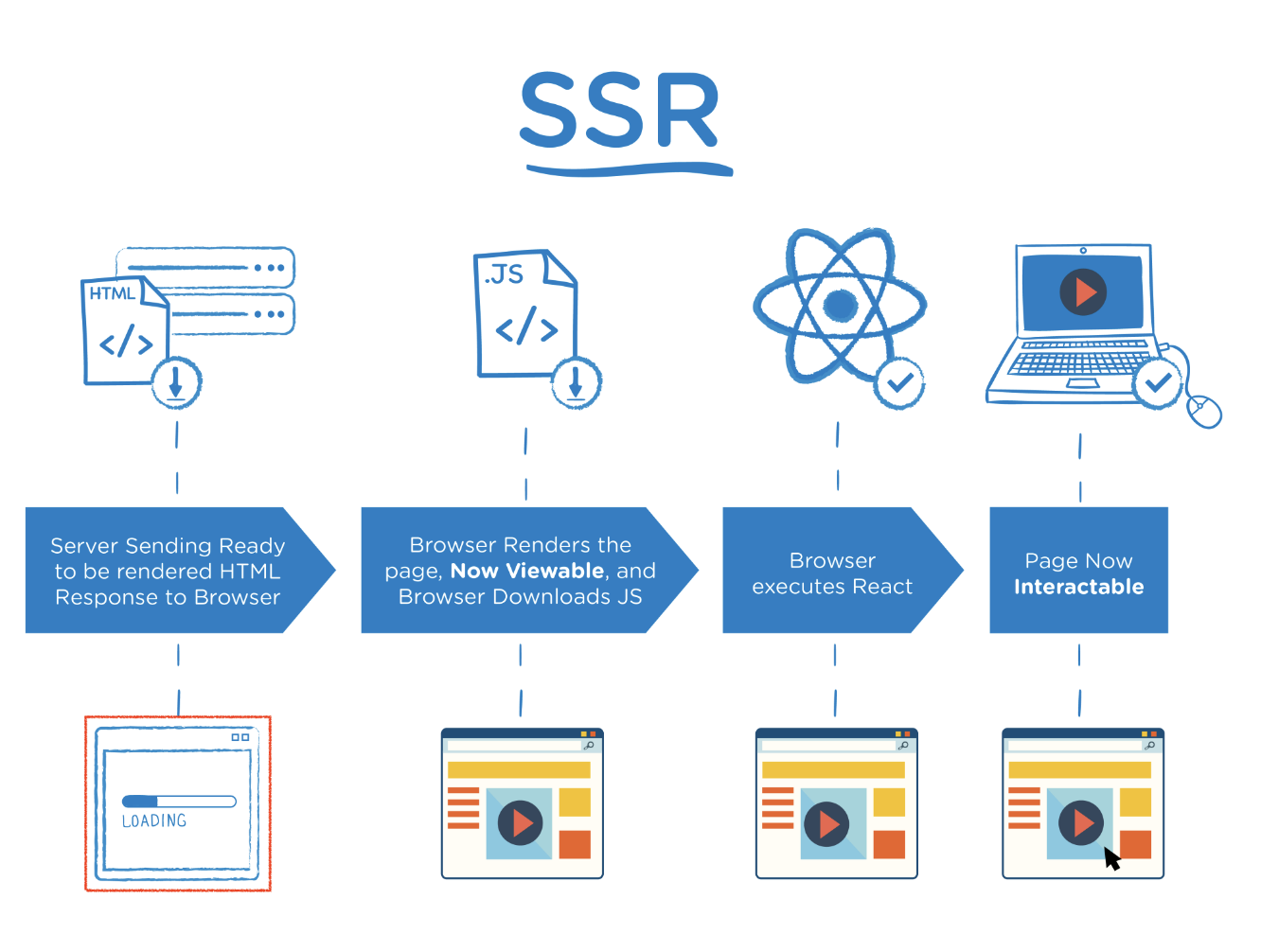
서버사이드 Server-Side Rendering
웹사이트 기준으로 서버측(개발자측)에서 사용자(클라이언트)에게 보여줄 페이지를 작업해서 보내주는 방식이며 과거 naver에서 모바일 블로그를 작성했을때 사용한 형식이라고 한다.
해당 방식은 모든 데이터가 매핑된 서비스페이지를 클라이언트에게 보여주기에 페이지를 구성하는 속도는 느려지나 사용자에게 보여주는 콘텐츠의 구성이 완료되는 시점이 빨라지며 SEO 또한 이점을 갖게된다.
(웹페이지 로딩시 한번에 화면 전체가 나오는게 아닌 화면에 뭔가 하나씩 나타나는 형태이다.)
순서
1. 클라이언트의 요청으로 서버에 웹페이지 및 특정 리소스를 요청하며 시작
2. 서버처리 - DB쿼리, 서버측 스크립트 실행 및 데이터를 HTML로 조립 및 HTML 생성
3. 응답전송 - HTML파일을 HTTP 응답으로 클라이언트에 전달
4. 브라우저 렌더링 - 브라우저가 해당 HTML응답을 받아 렌더링 및 화면출력
출처 : The Benefits of Server Side Rendering Over Client Side Rendering
장점
1. 데이터의 위조 가능성이 현저하게 줄어든다
2. 데이터 처리를 서버에서 담당하기에 클라이언트의 리소스 부담이 줄어든다.
3. SEO 성능의 향상 (검색엔진이 해당 페이지를 쉽게 크롤링가능 -> SEO는 밑에서 설명)
단점
1. 서버가 작업을 전담해서 작업하기에 많은 자원이 소모된다.
2. 새 페이지를 요청할떄마다 서버가 처리하고 응답하기에 서버가 느릴경우 지연이 발생한다.
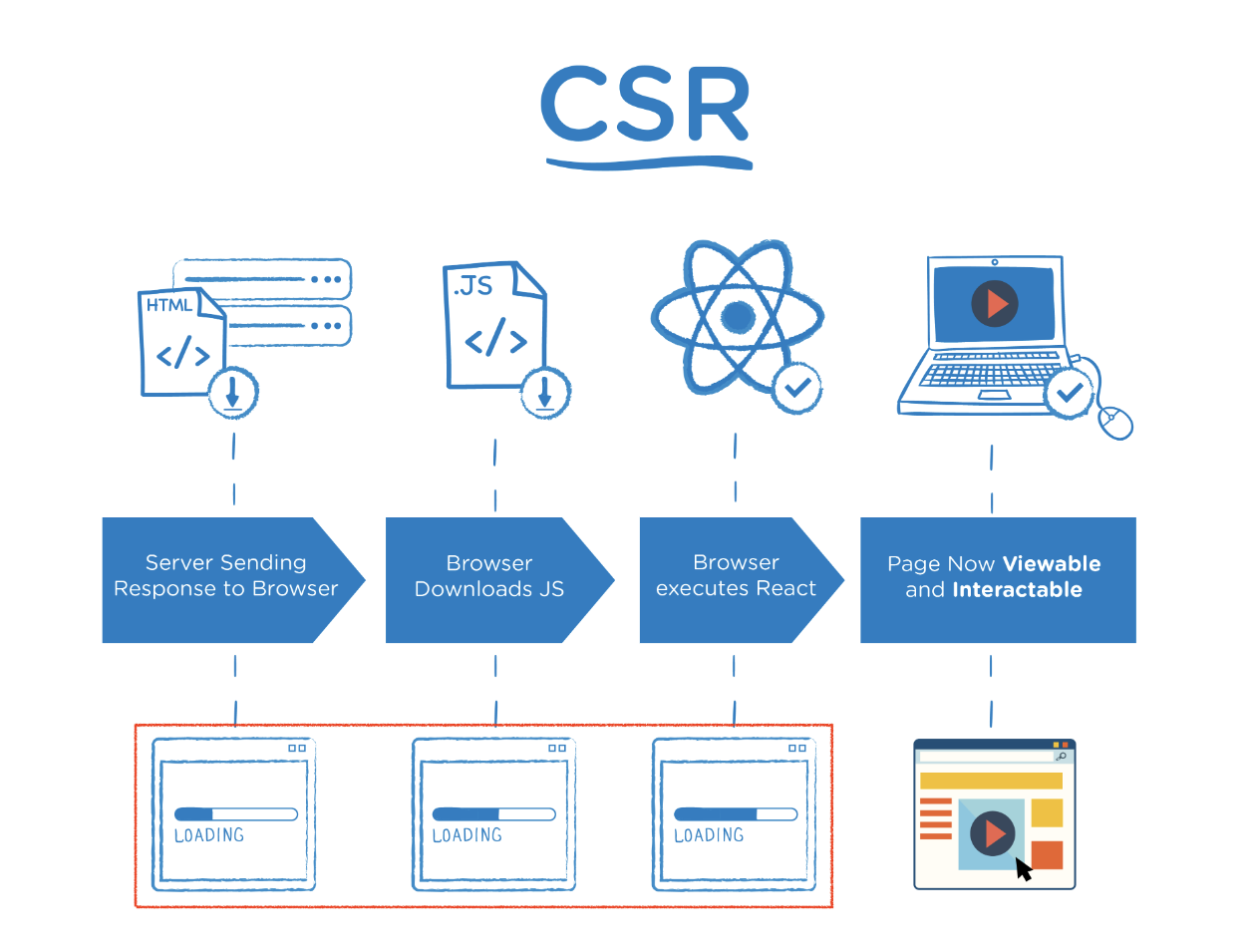
클라이언트 사이드 Client-side Rendering
클라이언트가 입력한것을 수신해 데이터만 넘어온 상태에서 JS가 HTML로 만들고 이를 애플리케이션에서 해석해서 표시하는것이다.
초기 전송되는 페이지의 속도는 빠르나 서비스에서 필요한 데이터를 클라이언트에서 추가로 요청하고 재구성하기에 실제 페이지 완료시점은 SSR보다 느려진한다
(즉, 일단 다 받아오고 조립하는 형식으로 하얀화면이 오래 나타난다)
출처 :The Benefits of Server Side Rendering Over Client Side Rendering
장점
1. 서버 유지비용이 줄어든다.
2. 로딩된후 페이지간 전환시 새로운 페이지를 서버에 요청할 필요없이 더 빠른 화면전환이 가능하다.
3. 네트워크가 끊기더라도 일부 기능의 유지가 가능하다
단점
1. SEO 성능이 낮다.
2. 클라이언트에서 데이터 처리가 이뤄지기에 보안상 비즈니스 로직이 공개될 우려가 있다..
3. 동적인 데이터의 경우 CSR은 서버에 계속 데이터에 대한 요청을 보내는데 이로인해 대기시간이 생긴다.
클라이언트 컴퓨터의 처리 부담이 많아진다.
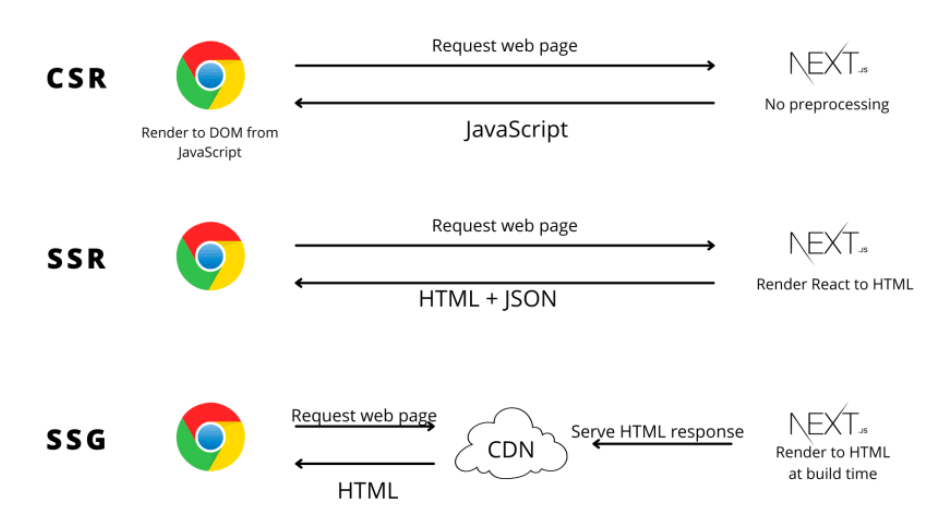
정적 사이트 생성 Static Site Generation
최근에 각광받는 방식으로 각 페이지를 빌드시점에 정적파일로 생성하고 클라이언트가 요청할때 이것을 넘겨주는 형식이다.
그리고 이것은 CDN과 연관되는데 SSG와 합쳐져 더욱 빠른속도의 로딩이 워지는것이다.
CDN(Content Delivery Network) - 서버에서 사용자가 요청하는 콘텐츠를 캐싱해두고 가까운 위치에서 콘텐츠를 제공하는 역할
구글의 CDN 예시
장점
1. 사전에 생성된 파일(정적파일)을 제공하기에 앞서말한 2개의 방법보다 훨씬 빠른 속도를 보여준다.
2. 정적이라 서버쪽 스크립트 실행이 없어 파고들 보안 취약점이 줄어든다. (하이재킹, 인젝션 공격, XSS 등..)
단점
1. 사전에 생성된 정적파일이라 실시간 변화하는 콘텐츠, 인터렉션 처리엔 제한요소가 생긴다.
2. 빌드 과정이 길어지며 새로운 콘텐츠 추가, 업데이트시 전체 사이트를 재빌드 해야한다.
SEO
SEO는 검색엔진 최적화로 검색엔진은 웹을 크롤링 -> 콘텐츠 수집 -> 결과페이지 출력의 순서를 갖는데
여기서 콘텐츠를 크롤링하는 시점에서 웹페이지의 HTML을 보고 구조, 콘텐츠, 링크등을 이해하고 나름의 우선순위를 매겨 더 상위권에 노출되는 형태이다.
그리고 SSR의 경우 서버에서 직접 HTML을 가공해서 보내기 때문에 SEO 입장에선 훨씬 더 쉽게 크롤링이 가능하기 때문에 최적화가 가능해진다는 것이다.
결론
요약하자면
비교대상
SSR
CSR
SSG+CDN
속도(초기 로딩속도)
보통
느림
가장 빠름
비용
중간
가장 쌈
가장 비쌈
SEO
우수(SSG와 동일)
낮음
우수(SSR과 동일)
보안
중간
낮음
가장 높음
다음의 표가 나타난다.
이를 토대로 naver가 17년에 CSR -> SSR로 변경을 하였는데 그이유를 나름대로 생각해보았다.
1. 특이 케이스의 문제
Naver라고 하더라도 많은 유저의 사람들이 이용하는 이상 특이 케이스에 대한 대응법 (2024년인데 아직 갤럭시S2를 쓴다던가 하는 케이스)을 만들어야했고 모든 케이스에 대응하는 방식보단 서버쪽에서 일괄적으로 만들어 넘겨주는SSR이 훨썬 더 효율적인 방식이라서 그런것 같다.
2. 대기시간의 최소화
구글 리서치에 따르면 웹사이트의 로딩시간이 3초가 넘어가는 시점부터 접속자 30% 이상이 해당 페이지를 이탈하며
5초부턴 90% 이상이 이탈하는 경향이 있다고 한다.
유저이탈을 방지하기위해 구글에선 공룡이 점프하는 게임을 제작했다고 생각한다.
네이버 또한 리서치 결과를 토대로 시간이 조금 오래 걸리지만 화면에서 무언가 출력되는 모습을 보이기 위해 해당 방식을 사용했다고 생각한다.
마지막으로 성능상 직접 진행해본사람의 글로 포스팅을 끝내겠다
조건 : JS파일을 CDN에서 받는경우
CSR
소요시간 : 24~50ms
(API 서버에 데이터를 요청했을떄)AWS 데이터 센터 : 117ms ,GCP : 70ms
SSR
소요시간 : 70ms
CSR이 SSR보다 약 2.9배 빠르게 html쉘을 렌더링 하였다.
DB와 여러번 통신을 주고받아야 할경우 SSR이 DB와 물리적으로 가까운 서버에서 실행되기에 CSR보다 유리하다
@PostMapping("/sendEmailID")
public ResponseEntity<?> sendIDEmail(@RequestParam("email") String email, HttpSession session) {
if (memberDAO.memberInfoByEmail(email) != null) {
// 세션에 인증용 번호 저장
email = email + "@naver.com";
int checknum = memberService.sendIDEmail(email);
session.setAttribute("authCode", checknum);
return ResponseEntity.ok(checknum);
} else {
return null;
}
}
초기에 void를 사용했으나 정상적으로 작동했음에도 error가 나타났다 이를 찾아보니
AJAX 요청은 응답 본문(return)이 없는 경우 클라이언트 측 JavaScript나 jQuery에서 이를 오류로 해석할 수 있습니다.
즉, return이 null이라 작동되어도 error가 나타났던것이다.
ResponseEntity<?> 반환 타입 AJAX 요청의 경우, ResponseEntity를 사용응답 본문(예를 들어, JSON 객체)과 함께 상태 코드를 반환함으로써 클라이언트 측에서 예상하는 응답 형식을 충족시킬 수 있습니다. ResponseEntity의 경우 return과 동시에 상태코드(200, 300...)를 반환하기에 ajax에서도 이게 실패했는지 아닌지 명확하게 인지할수 있게된다.
서비스 코드
랜덤 난수 생성으로 이를 통한 검증진행
@Autowired
JavaMailSenderImpl mailSender;
public int sendIDEmail (String email) { //난수의 범위 111111 ~ 999999 (6자리 난수)
Random random = new Random();
int checkNum = random.nextInt(888888)+111111;
//이메일 보낼 양식
String toMail = email;
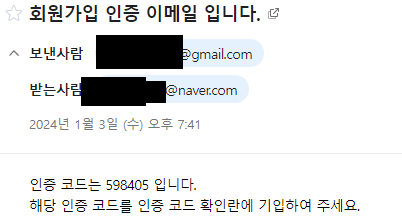
String title = "회원가입 인증 이메일 입니다.";
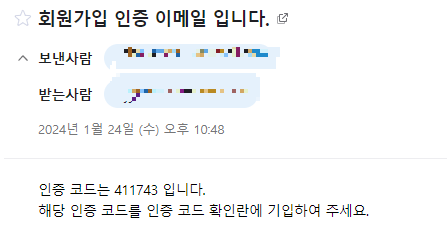
String content = "인증 코드는 " + checkNum + " 입니다." +
"<br>" +
"해당 인증 코드를 인증 코드 확인란에 기입하여 주세요.";
try {
MimeMessage message = mailSender.createMimeMessage(); //Spring에서 제공하는 mail API
MimeMessageHelper helper = new MimeMessageHelper(message, true, "utf-8");
helper.setTo(toMail);
helper.setSubject(title);
helper.setText(content, true);
mailSender.send(message);
} catch (Exception e) {
e.printStackTrace();
}
System.out.println("랜덤숫자 : " + checkNum);
return checkNum;
}
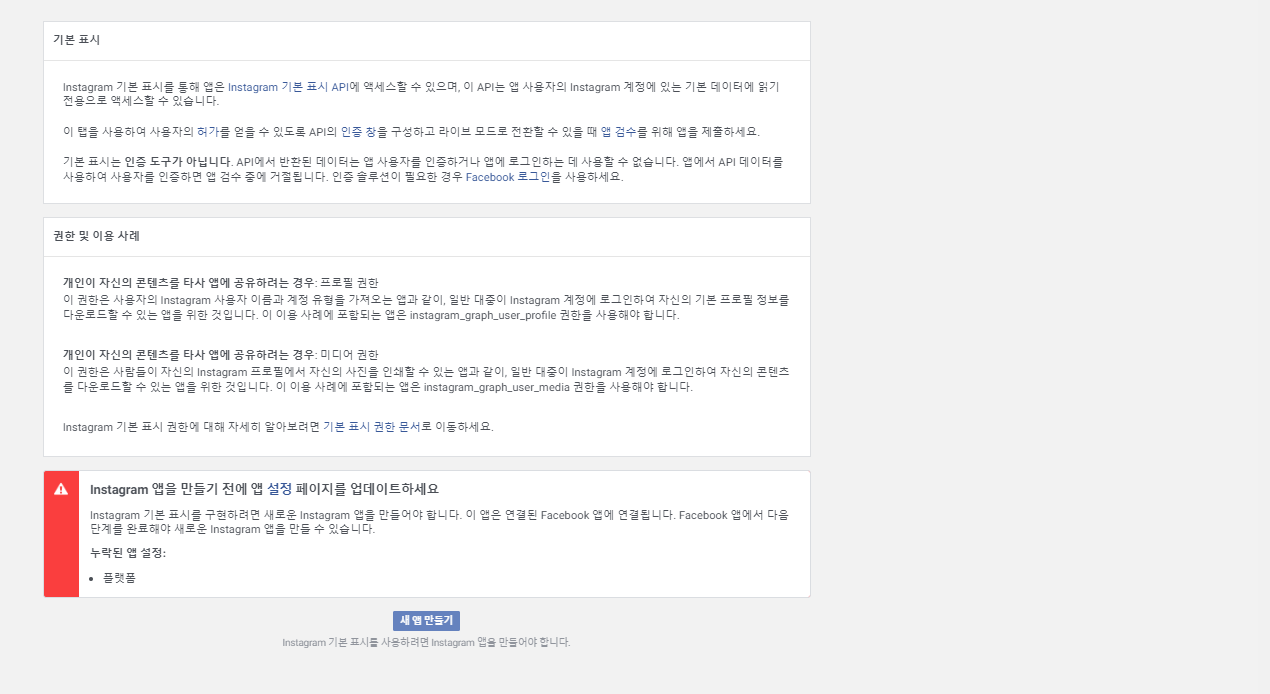
단기 실행 코드 발급용 기본 form
https://api.instagram.com/oauth/authorize
?client_id={app-id} //(A)
&redirect_uri={redirect-uri} // 동일하게 입력한 URL
&scope=user_profile,user_media //그대로
&response_type=code //그대로
수정한 form
https://api.instagram.com/oauth/authorize
?client_id=29..37
&redirect_uri=https://localhost:8989/
&scope=user_profile,user_media
&response_type=code
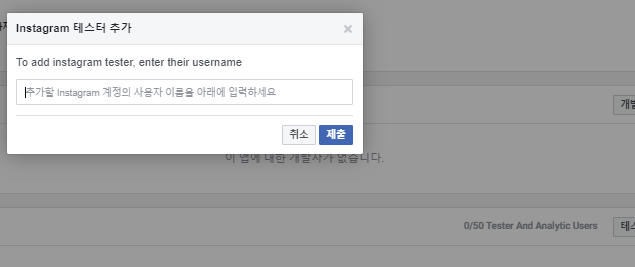
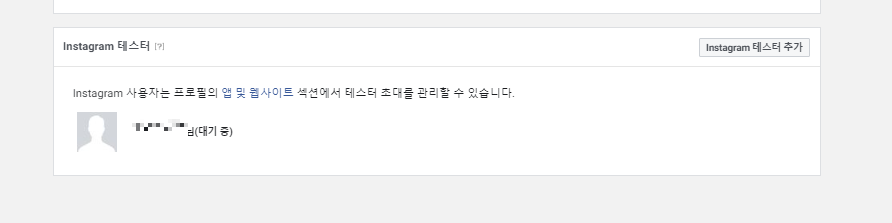
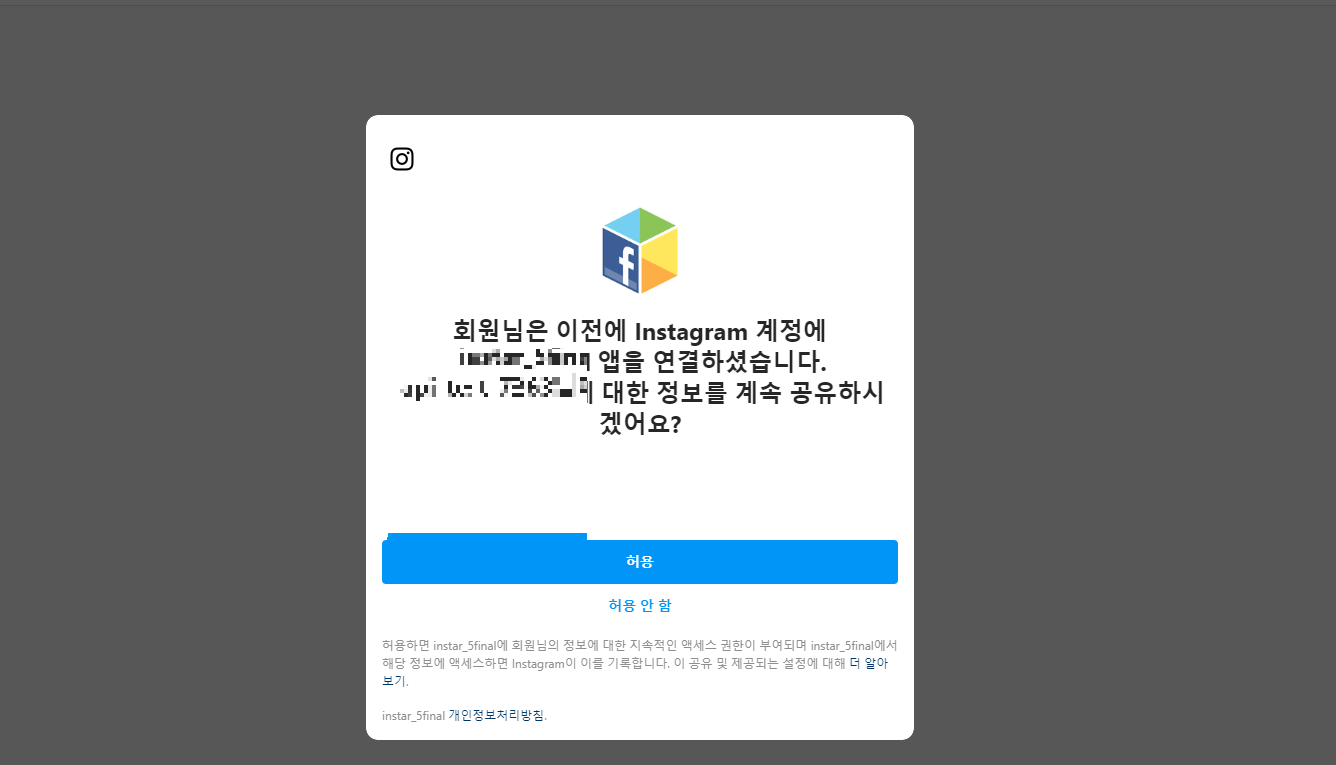
만일 문제가 없다면 해당 사진처럼 허용 여부를 물어볼것이다 (띄어쓰기 주의!, 이미 승인한 상황이라 계속 공유할지 물어보는것이다.)
2. 허용을 눌러 상단 URL을 복사
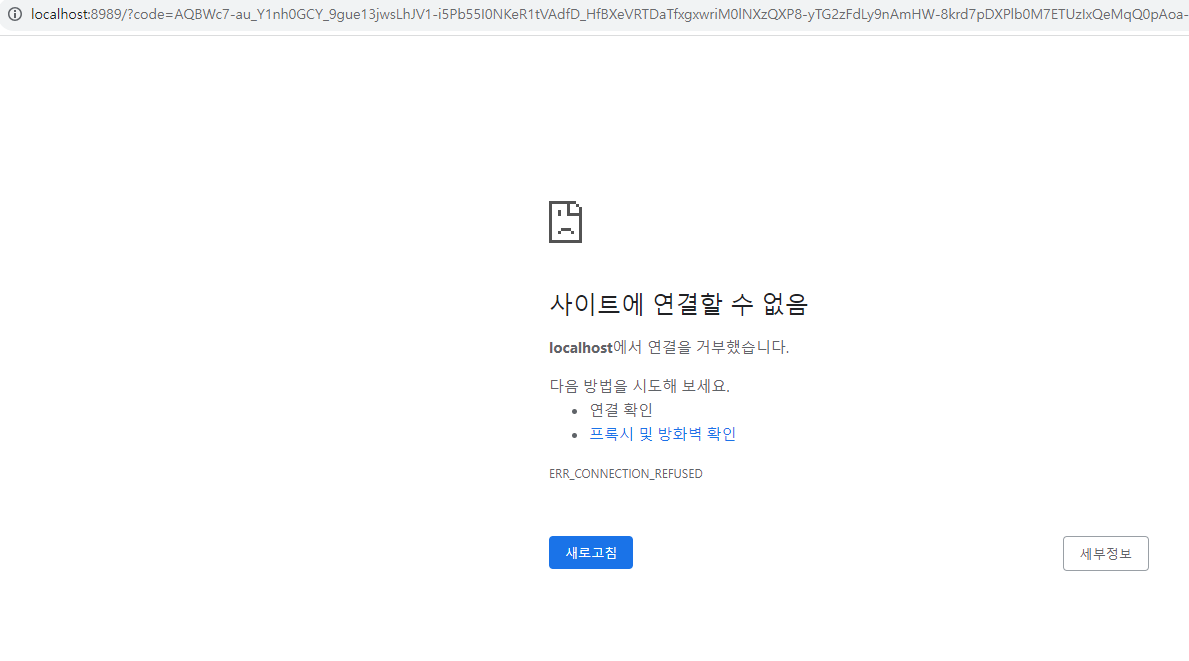
설정에 따라 다르겠지만 현재 https에서만 접근을 허용하나 http인 서버를 강제로 https로 입력하여 코드를 얻어낸 모습이다.
이것은 현재 1시간 짜리 단기 코드이며 이를 활용해 장기 사용 토큰으로 변경해야한다.
하단의 코드는 전체 URL이며 여기서 code뒤에 있는 부분만 활용한다
code 뒤쪽에 보면 #_가 붙는 경우도 있는데 #_는 날리고 사용한다
https://localhost:8989/?code=AQBWc7-au_Y1nh.....BrFQ#_ -> 여기 전체에서
AQBWc7-au_Y1qf1..BrFQ -> 요거만 사용할 예정
3. 해당 코드를 활용해 post요청을 전송
리눅스의 경우 cmd에 crul 코드 전송이 가능하지만.. 윈도우는.. 행운을빕니다..
장기 토근 발급 교환코드 기본 form
curl -X POST \
https://api.instagram.com/oauth/access_token \
-F client_id={app-id} \ 9번째 사진 (A)
-F client_secret={app-secret} \ 9번째 사진 (B)
-F grant_type=authorization_code \ 그대로
-F redirect_uri={redirect-uri} \ 9번째 사진 URL
-F code={code} 방금 발급받은 코드 (#_ 지운 코드)
수정한 form
curl -X POST \
https://api.instagram.com/oauth/access_token \
-F client_id=29..37 \
-F client_secret=98..6b9 \
-F grant_type=authorization_code \
-F redirect_uri=https://localhost:8989/ \
-F code=AQBWc7-au_Y1nh..JgBrFQ
정상적으로 돌아갔을경우 상단의 사진과 같은 결과가 출력된다 (해당 코드 장기토큰에서 사용할 예정이니 저장해두기)
IGQWRO....3VE9ndwZDZD", "user_id": 650...15
4. 정상적으로 받아왔는지 테스트하기
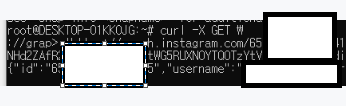
curl -X GET \
'https://graph.instagram.com/{user-id}?fields=id,username&access_token={access-token}'
여기에서 방금 받아온 id, 토큰값을 변경하기
curl -X GET \
'https://graph.instagram.com/650...15?fields=id,username&access_token=IGQWRO....3VE9ndwZDZD
자신이 가져오기로한 계정 이름이 username과 동일한지 확인해보자
여기까지 진행한걸 축하한다 드디어 인스타 1시간짜리 연결이 완성되었다.
현재까지 진행한건 단기 토큰으로 이를 장시간 사용하기 위해선 장기토큰으로 바꿔줘야한다.
장기 토큰 가져오기
만일 토큰 기간이 다되었단 에러가 나타날경우 바로 위의 단기 토큰 가져오기를 다시 진행해주시면 됩니다
(1시간 이내로 작업하기)
장기 토큰 가져오기 기본 form
curl -i -X GET "https://graph.instagram.com/access_token
?grant_type=ig_exchange_token //그대로
&client_secret={instagram-app-secret} // (B)
&access_token={short-lived-access-token}" //방금 발급받은 1시간짜리 토큰값
작성 예시 (해당 코드는 가독성을 위해 이렇게 작성되었지만 crul에서 가끔 못읽는 경우도 있으니 1줄로 보내주자!..)
curl -i -X GET "https://graph.instagram.com/access_token
?grant_type=ig_exchange_token
&client_secret=98..b9
&access_token=IGQW...ZDZD"
즉, 이렇게 입력해줘라
curl -i -X GET "https://graph.instagram.com/access_token?grant_type=ig_exchange_token&client_secret=98..b9&access_token=IGQW...ZDZD"
완료시 cmd에선 다음과 같이 출력되며 expires_in은 sec로 약 60일간 유효한 토큰을 얻은것이다.
만일 해당 토큰이 만료될경우 다음과 같은 방법을 사용한다.
장기토큰 재발급 받기
고맙게도 이건 쉽다.
장기 실행토큰 새로 고침 기본 form
curl -i -X GET "https://graph.instagram.com/refresh_access_token
?grant_type=ig_refresh_token //그대로
&access_token={long-lived-access-token}" //60일짜리 토큰
적용한 form(이거도 1줄로 써주자)
curl -i -X GET "https://graph.instagram.com/refresh_access_token
?grant_type=ig_refresh_token
&access_token=IGQWROUFAwcT...BQQZDZD"
여기까지 문제없이 따라왔다면 마지막으로 검색해보며 포스팅을 끝내겠다
URL 기본 form
https://graph.instagram.com/{app-id}/media?fields=id,media_type,media_url,permalink,thumbnail_url,username,caption&access_token={access_token}
{app-id}는 (A)를, access_token은 아까 발급받은 1시간, 60일 짜리 토큰 아무거나 사용하면 된다.
적용 form
https://graph.instagram.com/65..15/media?fields=id,media_type,media_url,permalink,thumbnail_url,username,caption&access_token=IGQWRQV...QZDZD
해당 url을 입력할경우 json 형태로 자신이 원하는 인스타 데이터를 가져올수 있게된다!
가상의 인터넷 환경에서 메세지를 주고받기 위해선 상호간의 위치를 지정할수 있는 주소가 필요한데 이를 IP주소라고 칭한다.
초기의 인터넷 환경이 작았을땐 다이렉트로 연결하면 무방했지만 점차 웹은 더 넓은 영역을 갖게되었고 이를 보완하고자 나타난것이 IP 프로토콜이다.
IP는 지정한 주소에 데이터를 전달 및 패킷이란 단위로 데이터를 전달한다.(출발 및 목적지 IP, 기타 정보로 통상적으로 1500byte로 전달)
IP프로토콜의 한계
1. 비연결성(Connectionless)
클라이언트와 서버가 한번 연결을 맺은후 서버가 응답을 마치면 연결을 끊는것(쉽게 말해 줄서있던사람이 용건이 끝나면 보내되 추가적인 용건이 생긴다면 줄 맨뒤로 보내버리는것) -> 그때마다 핸드쉐이킹을 진행해야 하기에 오버헤드가 발생할 여지가 있다.
만일 연결을 유지할경우 서버는 이를 위해 지속적인 자원을 할애해야하며 이는 곧 서버의 효율저하를 초래한다. (서버 자원의 효율화)
오버헤드를 줄이기 위해서 HTTP의 KeepAlive속성을 사용할수 있다 (일정 시간동안 서버-클라이언트간 패킷 교환이 없을경우 상대방에게 패킷을 주기적으로 보내며 이에 대한 응답이 없을경우 연결을 끊어버리는것 )
요청을 받을경우 상대의 상태가 어떻든(꺼져있거나 주소가 다르거나 하여도) 일단 보내고 연결을 끊어버리기에 의도한 순서나 결과에 맞지 않는 결과가 출력된다.
2. 비신뢰성
중간에 패킷이 사라지거나(패킷소실), 패킷의 순서가 다를경우(1500Byte가 초과될경우 패킷을 분할하여 보내나 모두가 동일한 경로로 가지 않기 때문에 순서가 다르게 도착할 우려가있다.)
3. 프로그램 구분 불가능
동일한 IP를 사용하는 서버에서 통신하는 애플리케이션이 2개 이상일경우 어떤 애플리케이션으로 전달해야할지 구분이 어렵다
이러한 문제는 후술할 TCP/UDP를 통하여 해결하였다.
오버헤드 - 어떤 처리를 하기위해 들어가는 간접적인 처리시간
TCP/UDP
Transmission Control Protocol (TCP) - 전송 제어 프로토콜
데이터를 보내는데 연결이 필요하다. ->핸드쉐이크를 통한 목적지 상태를 점검 (IP프로토콜 3번)
자료가 스트림 형태로 전송되며 타 컴퓨터에서 수신되어 링크가 생성되는 연결기반이다.
3way-hanshake를 통한 작업이 많기에 신뢰성, 연결성이 보장되나 속도가 떨어진다 (실질적인 데이터 전송이 이뤄지기전 진행하는 과정으로 목적지의 상태가 멀쩡한지 확인하는 과정이 추가된다. -> IP프로토콜 1번 해결)
데이터 전달 보증 - 패킷소실이 일어나도 클라이언트가 해당 사실을 인지할수 있도록 알려준다(Sequence number 참조) -> IP프로토콜 2번 해결
가상회선 방식 - 데이터 전송전 논리적인 연결이 설정되는데 각 패킷마다 가상회선 식별번호(VCI, Virtual Circuit Identifier)가 포함되어 모든 패킷이 전송되면 가상회선이 사라지고 패킷들은 전송된 순서대로 도착한다. (하단의 AcknowledgmentNumber 참조)
서버에서 내부적으로 최적화가 가능하지만 서버 자원측면에서 안좋기에 가급적 클라이언트에 재요청하는 방식
TCP 헤더의 모습
Source port - 출발지의 포트 번호
Destination Port - 목적지 포트번호
Sequence number - 바이트 단위로 순서화되는 번호로 TCP 세그먼트 첫번째 byte에 부여되며 이를통해 3way handshake가 이뤄지고 흐름제어 기능을 제공한다 -> 데이터 첫 번째 비트에 할당되는 임의의 32비트, 한번의 연결에서 한번만 사용되며 동일한 연결에서 다른 데이터 전송을 위해 다른 시퀀스 번호를 사용해야한다.
AcknowledgmentNumber(확인번호) - 수신을 기다리는 다음 byte번호 (마지막으로 수신에 성공한 번호의 +1)
Reserved - 에약된 필드 (현재는 미사용)
Window - 자신의 수신 버퍼 여유용량 크기를 통보하여 얼만큼의 데이터를 받을수 있는지 보여줌
U (Urgent, 긴급비트) - 내가 지금 보내는 데이터의 우선순위가 높음 (Urgent Pointer과 세트)
S (SYN 비트, 동기화비트) - 동기화 비트, 상대방과 연결을 시작할떄 사용되는 플래그 (핸드쉐이크에 사용)
A (ACK 비트, 승인 비트) 요청에 대한 응답을 진행할때 사용되는 플래그 (핸드쉐이크에 사용)
P (Push 비트) - Tcp 버퍼가 일정한 크기만큼 쌓여야 넘기는데 이에 상관없이 계속 데이터를 밀어넣겠다 (유튜브 버퍼링)
R (Reset 비트) - 초기화 비트, 연결된 상태에서 어떤 문제가 발생했을때 연결을 리셋하게됨
F (Fin비트, 종료비트)
User Datagram Protocol (UDP)
비연결성 - 데이터를 보내는데 연결이 필요하지 않다. -> 핸드쉐이크를 통한 연결상태 점검과정을 생락하고 일방적으로 보냄
UDP의 경우 단순하게 테이터만 보내기 때문에 신뢰성을 보장하지 않으나 가볍고 속도가 빠르다 -> 데이터를 효율적으로 보내야하는 응용프로그램, 게임은 직접적인 기능떄문에 UDP를 사용한다.
IP와 비슷하되 Port와 체크섬이 추가된다
데이터그램 방식 - 데이터 전송 전에 송/수신자 사이에 가상 회선 (논리적 경로)를 설정하지 않고, 패킷들이 각기 독립적으로 전송되는 방식 -> 이로인해 전송되는 순서가 바뀔 여지가 있다.
체크섬 - 중복검사의 일종으로 송신된 자료의 무결성을 보호하는 방법이다. 주로 해쉬값 비교를 통해 이뤄지며
3way handshake 연결과정
1. SYN 요청 (클라이언트 -> 서버) -> 클라이언트가 서버에 연결 요청을 하기위해 SYN 데이터를 보낸다
SYN -1, ACK - 0
해당 과정에서 window크기, 최대 세그먼트 크기 등 정보를 같이 보낸다 (window가 2000비트, 최대 세그먼트 크기가 200비트인경우 최대 10개의 세그먼트가 전송된다)
2. SYN + ACK (서버 -> 클라이언트) -> 요청을 받은 서버는 접속요청에 응답하기 위해 (SYN + ACK) 데이터를 보낸다. 해당 포트상태
서버측 클라이언트는 SYN, ACK로 응답한다
ACK는 여기에 window크기, 최대 세그먼트 크기 등 정보를 같이 보낸다 -> window가 2000비트, 최대 세그먼트 크기가 200비트인경우 최대 10개의 세그먼트가 전송된다
SYN에서 사용되는 시퀀스 번호와 클라이언트의 SYN과 다르며 서버는 자신의 window와 최대 세그먼트 크기를 클라이언트에 전달한다. (ACK의 승인번호는 수신된 시퀀스 번호보다 1만큼 크다)
ACK - 1, SYN - 1 (SYN이 1인 이유는 자신도 정상적으로 받았음을 의미하면 동시에 ACK를 1로 바꿔 응답할 준비가 되었음을 알림)
3. ACK (클라이언트 -> 서버) -> 서버의 승인이 떨어졌으니 자신이 필요로 하는 데이터를 보낸다.
SYN에서 사용되는 시퀀스 번호와 클라이언트의 SYN과 다르며 서버는 window와 최대 세그먼트 크기를 클라이언트에 전달한다. (ACK의 승인번호는 수신된 시퀀스 번호보다 1만큼 크다)
ACK - 1, SYN - 0 (연결이 완료되었기에 SYN은 0으로 바꿔버리고 연결간 데이터 전송을 위해 ACK는 1 유지)
3way handshake 종료과정
1. FIN (클라이언트 -> 서버) -> 사용이 끝났으니 종료할거라 플래그를 보냄.
임의의 시퀀스 번호로 메시지를 서버로 전달
FIN - 1, ACK - 0 (FIN은 끝임을 알리기 위해 1로 변경, 연결을 끊기 위해 ACK는 0으로 변경)
2. ACK + FIN (서버 -> 클라이언트) -> FIN에 대한 응답을 잘 수신했고 나도 끊기위해 FIN 플래그를 보냄
SYN에서 사용되는 시퀀스 번호와 클라이언트의 SYN과 다르며 서버는 window와 최대 세그먼트 크기를 클라이언트에 전달한다. (ACK의 승인번호는 수신된 시퀀스 번호보다 1만큼 크다)
서버는 클라이언트의 플래그를 FIN - 1, ACK - 1 (ACK는 클라이언트가 보낸 FIN을 정상적으로 받았음을 알리기 위해 1로 변환, FIN은 서버도 클라이언트와 끊음을 알리기 위해 1로 변환)
해당 과정이 끝날경우 클라이언트에서 서버측 연결은 종료된다
3. ACK (클라이언트 -> 서버) -> 연결 정지에 대한 서버의 승인이 떨어졌으니 윗단계에서 끊고 동시에 정상적으로 종료됨을 알리는 데이터를 보낸다.
클라이언트는 FIN을 수신후 ACK 플래그 1 설정, 서버의 FIN 시퀀스 번호보다 1만큼 큰 승인버호를 클라이언트로 보낸다 (진짜 끝낸다고 요청을 보내면서 클라이언트의 FIN플래그도 0으로 바꾼다)
상단의 이론을 진행하며 IP가 어떤식으로 소통하는지 확인하였다. 그렇다면 우리는 실질적으로 100.100.100.1이 아닌 naver.com과 같은 형태로 진행되는데 이에 대해서도 설명하겠다.
DNS(Domain Name System)
IP만 알면 되는데 DNS를 사용하는 이유 - IP는 기억하기 어렵고 IP는 변경될 우려가 있다
서버에서 망 사용료를 연체하여 해지됬으나 이후 다시 IP를 개설하여도 이 사실을 모르는 사람들은 대다수가 기존의 사이트로 돌아오지 못할것이다.
google에 접속하려고 할때 200.200.200.2라고 할경우 이것이 어떤 사이트인지 구분이 어렵고 google과 연관된 사이트라고 해도 IP를 다른곳에서 가져가버릴경우 200.200.123.4.. 220.324.123.2.. 이런식으로 연결해놔야 하기에 굉장히 불편하다.
그리하여 DNS라는 시스템을 고안하였으며 단순한 도메인명(google.com)만 입력할경우 이에 알맞는 IP로 찾아가게 되는것이다.
URL, URN, URI
URI (Uniform Resource Identifier) - 통합 자원 식별자를 의미한다.
인터넷에 있는 자원을 나타내는 유일한 주소를 의미하며 쉽게 말해서 URN + URL 두개를 합친 상위의 개념이다.
URN (Uniform Resource Name)
URI의 표준 포맷중 하나로 이름으로 리소스를 특정하는 URI이다.
URN은 리소스를 영구적이며 유일하게 식별이 가능한 URI다.
실제 자원을 찾기 위해선 URN을 URL로 변환해 이용한다.
리소스에 어떻게 접근할지 명시하지 않고 경로와 리소스 자체를 특정하는것 -> 크롬에 PDF 파일 같은걸 던져보면 알것이다. (file://0.0.0.123/)
URL (Uniform Resource Locator)
네트워크 상에서 웹페이지 ,이미지, 동영상등 파일이 위치한 정보를 나타낸다.
어떻게 리소스를 얻고 어디서 가져올지 명시
www.google.com
HTTP의 역사
HTTP/0.9 - GET 메서드만 지원, HTTP 헤더X
HTTP/1.0 - 메서드(post,get,delete...), 헤더, 상태코드(200,300...) 추가
요청헤더 - http 버전이 생김
응답헤더 - 상태코드와 content-type이 생겨 html파일 외의 다른 타입의 파일도 전송가능
단기 커넥션 - connection 하나당 1개의 요청, 1개의 응답만 처리가능 -> 상단의 비연결성과 비슷한 맥락
HTTP/1.1 - 가장 범용적으로 사용됨
Persistent connection - 지정된 timeout 동안 연속적인 요청 사이에 커넥션을 닫지 않음 -> 비 연결성에 약간의 여유를 주었다
Pipelining - 커넥션에서 응답을 기다리지 않고 순차적으로 여러 요청을 연속적으로 보내 그 순서에 맞춰 응답받아 지연시간을 줄이는 방식 -> Head of Line Blocking같은 문제점이 많아 사장됨.
Head of Line Blocking - 우선순위로 들어온 응답시간이 길어질경우 그 뒤에 있는 응답시간도 길어진다.
HTTP/2.0 - HTTP 1.1 성능개선 + 확장
메시지 전송방식의 변화 : 바이너리 프레이밍 계층 사용
파싱, 전송속도 증가
오류 발생 가능성 저하
멀티플랙싱
HPACK 압축 - 헤더 중복값 개선
HTTP/3.0 - TCP대신 UDP를 이용한 QuIC 프로토콜 사용
3.0 미만은 전부 TCP 프로토콜을 활용했으나 해당 버전부턴 UDP를 사용
클라이언트와 서버를 구분해야 하는 이유 -> 각자의 역할에 집중(독립적인 발전) 가능하기 때문이다.
리퀘스트, 리스폰 구조로 클라이언트는 서버에 요청을 보내고 응답을 대기하다 메시지가 오면 확인만 하면 된다
이것은 곧 서로 독립성을 의미하며 단적인 예시로 서버가 방금까지 JAVA를 쓰다 C로 넘어가도 클라이언트는 이것과 상관없이 그냥 요청만 하면 서버에선 이를 확인하고 보내줄수 있다
서버에선 비즈니스 로직 및 서비스만 구현하고 만일 문제가 발생할경우 클라이언트는 문제가 고쳐지기 전까지 다른작업을 진행하다 추후 완료되었을때 다시 접속만 하면 된다.