JPA (Java persistence API)
스프링 PSA에 의해서 (POJO를 사용하며 특정기술 사용을 위한) 표준 인터페이스를 정해두었는데 JPA의 자바의 ORM 기술의 EE표준중 1가지이다
JAP는 인터페이스이면서 동시에(라이브러리가 아님!) 구현체이므로 사용키 위해선 ORM 프레임워크를 선택해야한다
ORM (Object-Relation Mapping/객체-관계 매핑)
애플리케이션 Class와 RDB의 테이블을 연결해준다는뜻 으로 어플리케이션의 객체를 RDB(관계형 데이터베이스) 테이블에 자동으로 영속화 해주는 것이라고 보면 된다.
ORM은 DB테이블을 자바객체로 매핑하여 SQL을 자동으로 생상하지만 MAPPER는 SQL을 직접 명시해줘야한다
ORM - RDB(관계형 DB)의 관계를 Object에 반영하는것이 목적
Mapper - 단순 필드를 매핑시키는게 목적
DB 데이터 <- mapping -> Objcet필드 // 객체를 통한 간접적 DB데이터
객체와 DB데이터의 자동매핑 (메서드를 통한 데이터 조작, 객체간 관계를 바탕으로 SQL 자동생성)
Persistant API라고 칭할수 있다.
장점
- 객체와 테이블 자체를 매핑해서 패러다임의 불일치를 개발자대신 해결해준다.
- SQL이 아닌 메소드로 DB를 조작해 개발자는 객체모델만을 이용해 비즈니스 로직구성에 집중 가능
- 내부적으론 쿼리를 생성해서 DB를 조작하나 이것은 JPA가 해주는영역이다.
- 매핑하는 정보는 Class로 명시되어 ERD(개체-관계모델)를 보는의존도를 낮고 유지보수, 리팩토링에 유리
- MySQL DB를 사용하다 PostgreSQL로 변환시 기존DB를 PostgreSQL에 저장된 쿼리를 새로 짜야하는데 ORM은 자동으로 쿼리를 생성해주기에 부담이 적다.
- JPA는 네이티브 SQL 기능을 제공해주는데 관계매핑, 성능에대한 우려가 있을때 SQL을 직접 작성해 사용가능
단점
- 프로젝트 규모가 크고 복잡하여 설계가 잘못되는경우 속도저하 및 일관성을 무너뜨리는문제
- 복잡하고 무거운 쿼리는 속도를 위해 별도의 튜닝이 필수적이기에 불가피하게 SQL을 사용해야 할수도 있따
- 어렵고 비싸다...

패러다임의 불일치
객체나 DB간 불일치 하는것을 "패러다임의 불일치" 라고한다.
객체지향 VS 관계형DB
관계형DB와 객체지향은 갖고있는 사상이 다르다
객체지향 - 추상화, 캡슐화, 정보은닉, 상속, 다향성등 시스템 복잡성을 제어하는 다양한 장치 제공 (개발하기쉽게)
관계형 DB - 데이터 정규화를 통한 저장 (저장이 깔끔하게)
JPA는 애플리케이션과 JDBC 사이에서 동작하는데 JPA 내부에선 JDBC API를 사용하여 SQL을 호출하여 DB와 통신한다.
개발자가 ORM 프레임 워크에 저장하면 적절한 Insert SQL을 생성하여 DB생성하고 저장, 검색을 활용하면 적절한 SELECT SQL을 생성하여 객체에 매핑 및 전달
기존 EJB에서 제공되던 엔티티 빈을 대체하는 기술
객체를 통해 쿼리작성이 가능한 JPQL(Java Persistence Query Language)를 지원한다
JPA는 성능 향상을 위해 즉시로딩, 지연로딩등 몇가지 기법을 제공한다
#JAVA 표준은 Java SE(J2SE), Java EE(J2EE), JAVA ME(J2ME)가 있다? //다른페이지에 작성예정
자바컬렉션
JPA 1 - 2006년 -> 초기버전, 복합기 연관관계 기능부족
JPA 2 - 2009년 -> 대부분의 ORM 기능 포함, JAP Criteria가 추가
JPA 2.1 2013년 -> 스토어드 프로시저 접근, 컨버터, 엔티티 그래프 기능 추가
빌드그레이들 파일에서 확인후 인텔리제이에선
spring이 자동으로 적용해준다....
JDBC
SQL Mapper
JDBC는 SQL로 DB에 직접 접근할수 있도록자바에서 제공하는 API이며 Mybatis, jdbcTemplate이 그 예시다.
SQL<-Mapping-> Object 필드

TABLE - SQL용어로 DB에 들어가는 값을 구분해주는 KEY가 되는것이라 생각하면 된다.
//SQL 생성문
CREATE TABLE emp_table
( emp_id NUMBER NOT NULL, // DB에 보낼때 id는 emp_id에 기입
emp_name VARCHAR2(100) NOT NULL, // DB에 보낼때 이름은 emp_name에 기입
gender VARCHAR2(10) NULL, // DB에 보낼때 성별은 gender에 기입
age NUMBER NULL, // DB에 보낼때 나이는 age에
hire_date DATE NULL, // DB에 보낼때 생년월일은 hire_date에 기입
etc VARCHAR2(300) NULL, // DB에 보낼때 기타 내용은 etc에 기입
PRIMARY KEY (emp_id) );
//SQL 값 기입
INSERT INTO emp_table (emp_id, emp_name, gender, age, hire_date)
VALUES (1, '홍길동', '남성', 33, '2018-01-01');
INSERT INTO emp_table (emp_id, emp_name, gender, age, hire_date)
VALUES (2, '김유신', '남성', 44, '2018-02-01');
INSERT INTO emp_table (emp_id, emp_name, gender, age, hire_date)
VALUES (3, '강감찬', '남성', 55, '2018-03-01');
INSERT INTO emp_table (emp_id, emp_name, gender, age, hire_date)
VALUES (4, '신사임당', '여성', 66, '2018-04-01');
COMMIT;
//JPA 사용 예시
JPA는 애플리케이션과 JDBC 사이에서 동작한다
개발자가 JPA를 사용시 JPA 내부에선 JBCD API를 사용해 SQL을 호출하여 DB와 통신한다
즉, 개발자도 직접JDBC API를 호출하는게 아닌 JPA에 요청하면 여기에 내장된 JDBC API가 혼자 작동하는것

MemberDao에서 객체를 저장하고 싶을경우
개발자 : JPA에 Member 객체를 넘긴다 (개발자의 행동은 여기서 끝난다)
JPA : Member 엔티티 분석 -> INSERT SQL (삽입용)을 생성한다 -> JDBC API를 사용하여 SQL을 DB에 넣는다
- 엔티티에 필드 추가시 등록,수정,조회 관련 코드 모두 변경하는데 이것을 JPA가 모두 진행
- JPA는 수정메소드를 제공하지 않고 매핑된 데이터(테이블 데이터)를 조회하여 값을변경후 커밋하면 DB서버에 UPDATE문을 전송하여 혼자 UPDATE를 실행한다.
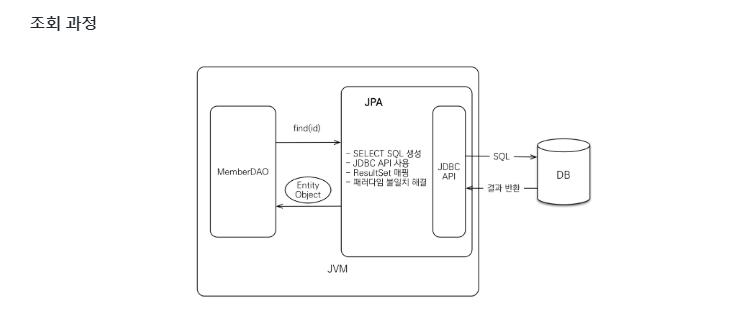
Member 조회기
개발자 : Member의 pk값을 JPA에 넘긴다
JPA : 엔티티의 매핑정보 기반 적절한 SELECT SQL을 생성 -> JDBC API를 사용해 SQL을 DB에 요청 -> DB로부터 결과를 받아 결과(ResultSet)를 모두매핑한다
쿼리가 JPA를 만들어주기에 Object와 RDB간 패러다임 불일치를 해결할수 있다.
객체와 관계형DB의 차이점
1. 상속관계
JAP는 객체의 참조로 연관관계 저장가능 ->
객체상속관계 : 부모가 값이 바뀌면 자식도 바뀌나 반대의경우는 그렇지 않다?
객체상속 관계에선 extnds, implements로 상속관계를 맺고 부모<->자식의 캐스팅(형변환)도 자유롭다
- 상속 받은 객체 (Album, Movie, Book)을 DB에 저장하려면 객체분해를 통해 Album객체를 Item과 분리해야하며 Item Table에 1개, Album 테이블에 2개의 쿼리를 작성해야한다.
- Album 객체를 DB에서 조회하러면 ITEM과 ALBUM을 조인해 가져온뒤 조회한 필드를 각각 맞는 객체(ITEM, ALBUM)에 매핑시켜 가져와야한다.
(쿼리 - DB에 데이터를 요청하는것)

2. 연관관계
객체는 참조를 사용하며 테이블은 외래키를 사용한다.
Member와 Team간 참조가 가능한가?
객체관게 : Member은 member.getTeam()의 형태로 참조가능, 반대의 경우는 참조불가
테이블관계 : 쌍방간 참조할 키(FK?)가 있기에 양측 참조가 가능

//외래키 - SQL 글에서 작성예정
RDB
ORM이란?
Object-Relational Mapping
자바의 객체와 관계형DB를 맵핑하는 것으로 DB의 특정테이블이 자바의 객체로 맴핑되어 SQL을 일일이 작성하지 않고 객체로 구현할 수 있도록 하는 프레임워크이다.
객체와 관계형 dB를 매핑한다는 뜻
ORM 프레임워크를 사용하면 객체를마치 자바 컬렉션에 저장하듯 저장하고 이에대해 ORM 프레임워크가 적절한 SQL을 생성해서 DB에 객체를 저장해준다
Hibernate
에서 가장 자주사용되는 프레임워크
Hibernate기반으로 만들어진게 ORM기술표준이 JPA다
JPA는 ORM기술표준이 구현한게 Hibernate 이므로 JPA를 사용하려면 Hibernate를 사용하면 된다.
DDL (Data Definition Language) - 객체생성,변경,삭제 명령어로 schema, domain, table, view, index를 정의,변경,삭제
ㄴ>종류 = create(생성), alter(변경,수정), drop(삭제), rename(재정의)
DML (Data Manipulation Language) - 데이터 조작어 (제어 명령어)
ㄴ>종류 = select(선택), insert(삽입), update(변경,수정), delete(삭제)
DCL (Data Control Language) - 객체 권한 부여 데이터의 보안, 무결성, 데이터 회복, 병행 수행 제어 등을 정의하는 데 사용하는 언어입니다. DB 관리자의 DB 관리목적
종류 = commit, rollback, grant, revoke
DELETE, DROP, TRUNCATE 차이점
DELETE - 데이터는 지워지나 용량은 줄지 않는다 - 테이블 남기기 (되돌리기 가능)
TRUNCATE - 용량이 줄고 인덱스등이 삭제되며 테이블만 잔존한다 - 테이블도 날리기 (되돌리기X)
DROP - 테이블 전체, 공간, 객체 삭제 - 전부삭제 (되돌리기X)

DB 관련 내용은 블로그내 다른글을 참조해주세요
사용하는 이유
1.JPA를 사용하면 자바 컬렉션에 저장하듯이 JPA 에게도 저장할 객체를 전달하면 된다.
코드의 간소화, 가독성 및 수정 용이
MySQL등 DB 벤더에따라 조금씩 다른SQL 문법때문에 애플리케이션이 DB에 종속되나 JPA는 직접 쿼리작성을 안해서 DB벤더에 독립적 개발이 가능하다.
CRUD 형태
- 저장: jpa.persist(member)
- 조회: Member member = jpa.find(memberId)
- 수정: member.setName("변경할 이름")
- 삭제: jpa.remove(member)
DDL문도 자동으로 생성해주기에 DB 설계 중심을 객체설계 중심으로 변경이 가능
2. 필드를 1개만 추가해도 SQL과 JDBC코드를 전부 수행해야했지만 JPA는 이를 대신 처리해주기에 개발자가 보다 maintenance(유지보수) 해야하는 코드가 줄어든다
객체와 관계형 DB를 매핑한다는 뜻이다.
3.패러다임의 불일치 해결
JAP는 연관객체 사용 시점에 SQL에 전달가능, 같은 트랜잭션 내에서 조회할때 동일성도 보장하기에 다양한 패러다임의 불일치를 해결한다.
4.성능
애플리케이션과 DB사이엔 성능 최적화 기회를 제공한다.
같은 트랜잭션 안에서는 같은엔티티를 반환하기 떄문에 DB와의 통신 횟수를 줄일수 있다.
또한 트랜잭션을 커밋하기전까지 메모리에 쌓고 한번에 SQL에 송신한다.
5. 데이터 접근 추상화와 벤더 독립성
RDB는 동일기능이라도 벤더마다 사용법이 달라 처음의 DB에 종속되고 변경이 어렵다
JPA는 DB 사이에서 추상화된 데이터 접근을 제공키에 종속이 되지 않도록한다.
DB가 변경되더라도 JAP에게 알려주면 변경이 가능하다.
6.JPA가 제공하는 API를 사용하면 객체를 DB에 저장하고 관리할때 개발자가 직접 SQL을 작성하지 않아도 된다.
JPA가 개발자 대신 적절한 SQL을 생성해서 DB에 전달 및 객체를 자동으로 매핑해준다
JPA는 내부적으로 JDBC API를 사용하는데 개발자가 직접 JDBC API를 활용하면
7. SQL 중심적인 개발에서 객체 중심으로 개발
SQL을 직접 다룰때의 문제점
1.생산성 저하
ㄴ> 100개의 테이블이 존재하면 100개의 CRUD를 일일이 작성해야한다. 그렇지만
CRUD - Create(생성), Read(읽기), Update(갱신), Delete(삭제)를 앞글자를 따서 만든 단어
(SQL은 작성, JDBC API로 SQl실행, 결과를 객체로 매핑)
2.SQL 의존적 개발
테이블에 1개의 칼럼을 추가하려면?
모든 SQL의 변경이 필요,
DDL 관련 모든 쿼리와 메소드의 변경필요
버그 발생시 직업 DAO를 열어 SQL을 확인해얗나다
ㄴ> 논리적인 계층 분할이 어렵다
3.패러다임의 불일치
하단참조
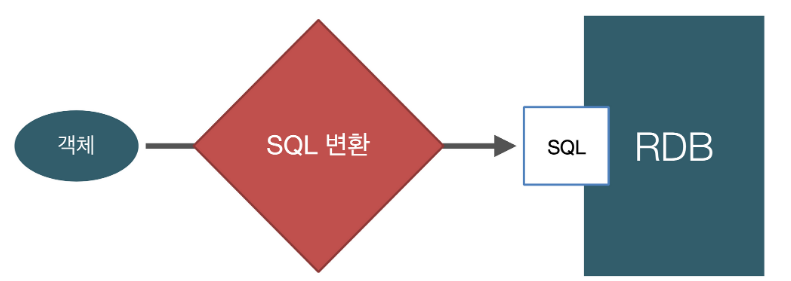
4. 객체 그래프 탐색
객체는 자유롭게 그래프 탐색이 가능해야하나 SQL을 이용해 조회한경우 초기 SQL에 따라 탐색범위가 저장되기에 제약이 발생한다 -> 이것때문에 DAO를 직접 열어서 SQL을 확인해야 탐색이 가능하다
(Member객체 에서 그래프를 통해 Category 까지 접근이 가능해야한다)

비교 - DB는 기본키의 값으로 구분하나 객체는 동일설비교(주소 비교 "=="), 동등성 비교(값 비교 "equlas()" ) 2가지가 있다
SQL을 통하여 기본키가 같은 객체를 불러와 매핑하면 동일성을 비교할때 false가 출려괴는데같은 로우지만 다른 인스턴스로비교하기 때문이다.
ORM 프레임워크 - 객체와 테이블의 매핑만 진행하면 대신 해결해준다객체는 객체끼리 알아서 생성하고 DB는DB끼리 맞도록 설계가 가능해진다.
지연로딩 - 객체가 실제로 사용될때 로딩하는 전략?
값이 필요한 시점에 JPA가 Team에 대한 SELECT쿼리를 날린다.
Member 및 Team 객체 각각 따로 조회하기에 네트워크를 2번타는데 Member를 사용시 TEAM도 필요하면 즉시 사용한다.
즉시로딩 - JOIN SQL로 한번에 연관된 객체까지 미리 조회하는 전략
Join을 통하여 연관객체 모두를 전부 가져온다
객체를영구보관하는 저장소 종류
RDB - 가장 많이쓰이는것
NoSQL - 2안으로 자주 채택
File - 객체 100만개를 Serialize(직렬화)하여 정렬하고
쿼리의 불일치
비즈니스 로직
JDBC Template
CRUD 쿼리에 TEL을 하나씩 다 추가해줘야한다?
UPDTAE MEMBER SET ...TEL = ?
벤더독립성
동일성(identical)과 동등성(Equivalent)
동일한 오브젝트 - 같은 레퍼런스를 바라보고 있는 객체라는말 (1개의 오브젝트이다) // "=="
동등한 오브젝트 - 같은 내용을 담고 있는 객체인지? // "equals"
참고사이트
https://girawhale.tistory.com/119
https://kim-oriental.tistory.com/20
https://velog.io/@jwkim/JPA-JPA%EB%9E%80-%EB%AC%B4%EC%97%87%EC%9D%B8%EA%B0%80
https://gmlwjd9405.github.io/2019/08/04/what-is-jpa.html
'JAVA' 카테고리의 다른 글
| 클래스 변수,인스턴스 변수 (1) | 2023.01.30 |
|---|---|
| 인터페이스란? (3) | 2023.01.13 |
| 지수와 가수 (1) | 2023.01.13 |
| 3항 연산자에 관하여 (2) | 2022.12.22 |
| 라이브러리와 프레임워크 (1) | 2022.12.20 |