OS는 직접적으로 하드웨어를 조작할수 있지만 응용프로그램은 OS가 제공하는 인터페이스를 통해 간접적으로 관리가 가능하다.
그렇다면 응용프로그램이 직접 하드웨어를 조작할 필요가 있을땐 어떤방식을 사용해야 할까?
이것을 도와주는게 시스템콜이다.
시스템콜
OS는 커널모드와 사용자모드로 나뉘어 구동되고 파일작성, 파일수정, 메세지 출력등은 커널모드를 사용하는데 이것을 사용자 모드에서 사용가능하도록 하는것 즉, 여러 커널영역의 기능을 프로세스가 하드웨어에 직접적으로 접근해 필요한 기능을 하도록하는것으로 SW 인터럽트(Trap)로 취급된다.
커널모드에서만 파일수정 등의 작업이 가능한건 권한수준이 다르게 설정되었기 때문이며 만일 사용자모드에서 접근을 허용할경우 기존의 정상적인 코드가 변경될 우려가 있기 때문이다.
시스템콜 진행 방식
1. 응용 프로그램에서 Trap을 발생시킨다.
2. 라이브러리에서 기능에 따른 시스템콜 고유번호가 레지스터에 저장, 해당 주소에 인터럽트를 건다.
3. 커널은 IDT엔트리를 참조해 알맞는 서비스 루틴을 수행한다.
인터럽트 서술자 테이블(Interrupt Descriptor Table,IDT) - 인터럽트 처리를 위해 서비스 루틴을 함수로 구현해놓고 각 함수의 시작점 주소를 등록해놓은 테이블로 IDT 위치를 가리키는 레지스터를 IDTR이라 칭한다.
(Trap 발생 -> IDTR에서 IDT를 확인 -> 해당 주소에 있는 함수(서비스 루틴)를 실행)
IDT
사용자모드의 프로세스가 SW인터럽트(Trap이라 표현한다)를 통하여 커널의 기능을 이용하기 위하여 프로세스 제어, 파일 조작, 자원관리 등의 작업을 지원한다
API는 응용프로그램에게 HW의 사용법을, 시스템콜은 HW를 직접 호출해 사용하는데 일반적으로 API를 더욱 자주 사용한다고 한다.
시스템콜이 아닌 API를 우선 사용하는 이유
1. 프로그램 호환성 -> 동일한 API를 사용하는경우 어떤 시스템(리눅스,윈도우)에서도 실행이 가능하다.
2. 사용이 편리해서 -> 시스템콜을 사용할경우 자세한 명세(cp in.txt out.txt..)가 필요한데 API가 이것을 대신해준다.
3. RTE
실행 환경 (RTE, Real time Enterprise)
이것은 OS에게 자신과 시스템콜 사이의 인터페이스를 제공하며 이를 활용해 호출자(사용자)는 시스템콜의 코드를 입력할 필요없이 API가 어떤방식으로 돌아가는지만 알고 있으면 된다.
시스템콜 종류
1. 프로세스 제어 - 프로세스 생성 및 종료, 메모리 적재 및 실행
2. 파일 조작 - 파일 생성 및 수정
3. 장치 관리 - 디바이스, I/O,
4. 정보 관리 - 데이터의 속성 설정 및 저장
5. 통신 - 메세지 송수신, 리모트 디바이스 탈부착
6. 보호 - Permission(권한) 획득 및 설정
정리
시스템콜 - 커널영역의 기능을 프로세스가 하드웨어에 직접적으로 접근해 필요한 기능을 하도록하는것
처리 순서
1. 시스템콜 발생(요청)
2. 사용자모드 -> 커널모드로 변경
3. IDTR에 있는 IDT의 시작주소를 참고해 이에 해당하는 서비스 루틴을 진행 (기 진행 데이터는 레지스터에 보관)
오브젝트 파일의 심볼테이블은 해당 오브젝트 파일의 심볼정보만 있어야하기에 다른 파일에서 참조되는 심볼의 정보는 저장이 불가능하다. (이것은 하단의 심볼간 중복 문제때문에 그렇다)
오브젝트 파일의 종류
중복문제 해결에 대한 설명전 오브젝트 파일의 종류에 대해 설명하겠다.
재배치가 가능한 오브젝트 파일 Relocatable object file
컴파일 결과로 생성되는 파일 (링킹 이전의 오브젝트 파일)
실행 가능한 오브젝트 파일 Executable object file
다른 오브젝트 파일과 합쳐져 생성된 실행파일 (링킹 이후 생성된 오브젝트 파일)
공유 오브젝트 파일 - Shared object file
DLL에서 사용되는 오브젝트 파일 (확장자로 .so를 갖는다)
심볼해석 (Symbol Resolution) - 링커가 입력이 들어오는 재배치 가능 오브젝트 파일들의 심볼테이블 정보를 바탕으로 각 오브젝트 파일의 심볼 참조를 정확하게 하나의 심볼 정의에 연결하는 작업이다.
1. 링커는 커맨드라인 입력순서대로 재배치 가능 오브젝트 파일과 아카이브 파일을 스캔한다(사진처럼 3가지로 구분하여 분리한다.)
2. 링커는 파일을 스캔할때마다 재배치 가능 오브젝트 파일인지, 아카이브 파일인지 확인하고 모든 심볼 참조를 정확히 하나의 심볼정의(심볼 테이블 엔트리)에 연결한다 (만일 해석되지 않은 심볼참조가 있는경우(UNDEF에 있는걸 전부 확인한후) 에러메세지와 즉시종료한다 -> 하단의 Strong이 복수일경우)
3. 심볼 테이블엔트리와 연결된경우 재배치를 진행한다.
아카이브 (archive) - 파일 전송을 위해 백업, 보관용 파일 또는 디렉토리로된 파일 (기록저장소)
심볼정의 - 해당심볼을 정의하는 심볼 테이블에 엔트리 (연결)
심볼참조 - 코드 상에서 해당심볼을 참조하는 부분
심볼의 종류
전역심볼
EX1) A에서 정의되고 B에서 참조한 심볼
non-static 함수 non-static 전역변수
EX2) A에서 참조하고 B에서 정의된 심볼
지역심볼
A에서 정의되고 A에서만 참조되는 심볼
static 함수/전역/지역변수
지역심볼의 해석
정의된 모듈 내부에서만 참조가 가능할뿐아니라 각 모듈 내부에선 지역심볼의 고유함을 보장하기 때문이다(한 파일 내부에서만 쓰니까 상관이 없다)
전역심볼의 해석
외부에서도 참조가 가능하기에 전역심볼의 참조에 대응되는 심볼정의를 현재 모듈의 심볼테이블에서 찾지 못할수도 있다 (A모듈에서 B모듈에 있는 전역심볼을 사용할경우 A모듈의 심볼테이블에선 찾을수 없다) 이러한 경우 컴파일러는 해당모듈이 오류가 아닌 다른 모듈에 정의된것을 가정하고 UNDEF(비명시됨)섹션인 심볼 테이블 엔트리를 만들어 나중에 링커가 다른 모듈의 심볼 테이블에서 찾아 심볼해석을 진행한다 (아는것부터 끝내고 모르는건 나중에 한다고 생각하면 된다)
그러나 전역심볼의 경우 여러모듈이 동일한 이름의 설정을 하는것도 가능한데 이것은 컴파일 단계에서 다른 모듈에서 동일한이름의 전역변수인지 확인할수 없기때문이다
온전한 심볼해석을 위해선링커는 심볼해석을 위해서 전역심볼의 중복문제를 우선 처리해야한다.
심볼 테이블 엔트리 -> 해당 심볼이 어떤 심볼인지 확인하는 용도
컴파일러가 .s파일에 담은 심볼의 정보를 바탕으로 심볼테이블을 구성, 이를 재배치 가능 오브젝트 파일의 .symtab섹션에 저장된다. (.s파일은 컴파일러가 출력한 어셈블리어 코드 (여기선 오브젝트 파일로 읽으면 될것이다) // .S는 개발자가 직접 작성한 어셈블리어 코드)
하단의 사진은 각 엔트리의 구조를 C언어 구조체로 표현한것이다.
심볼 테이블 엔트리
이름
설명
name
.strtab 섹션 내부 오프셋 저장
type
Function, data저장
binding
심볼종류를 나타내며 글로벌,로컬에 저장 (Strong, weak)
section
심볼이 할당될 섹션 섹션헤더 테이블 인덱스를 저장하며 실제로 존재하지 않는 Pseudo 섹션을 가리킬수도 있다.
value
심볼의 위치저장 재배치 가능 오브젝트파일 -> 섹션내 오프셋 저장 실행파일 -> 절대 가상주소 저장
size
심볼 데이터의 바이트 단위 크기 저장
Pseudo 섹션
섹션 헤더 테이블에 엔트리가 없는 섹션을 의미하는 것으로 재배치 가능 오브젝트 파일에만 존재하고 실행파일엔 존재하지 않으며 하단의 3가지 섹션으로 나뉜다
재배치가 이뤄지면 안되는 심볼인 ABS 섹션
다른 모듈에 정의되있는 심볼임을 나타내는 UNDEF 섹션
초기화가 되지 않은 전역변수를 위한 COMMON섹션 (심볼중복처리문제 참고)
전역 심볼 중복 문제
전역심볼은 초기화 여부에 따라 Strong 심볼과 Weak 심볼(초기화 안됨 EX : int x)로 구분되는데 Weak 심볼은 동일한 이름으로 여러번 정의될수 있는 특징이 있다. (상단의 사진 참조)
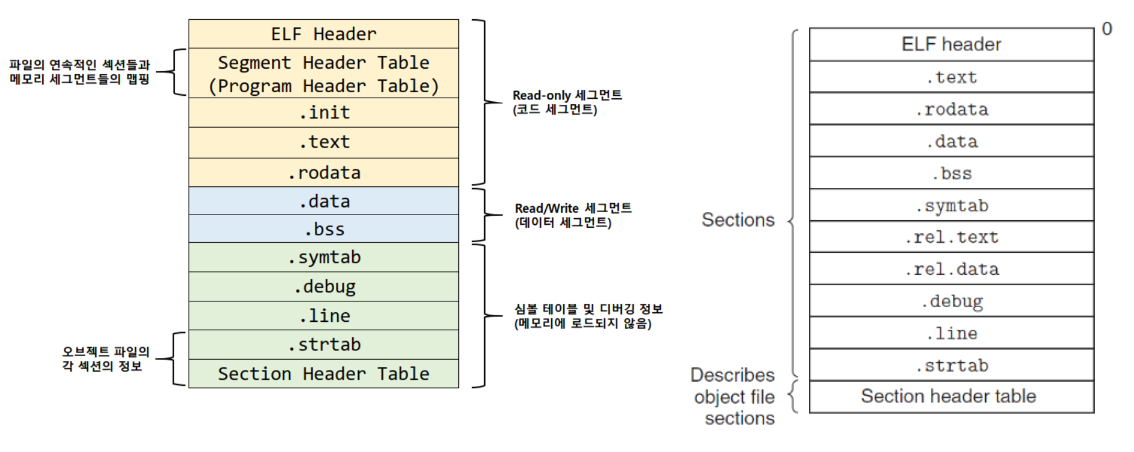
하단의 ELF파일 양식을 참고하길 바란다.
재배치 가능 오브젝트 파일(우측)
구분
설명
ELF헤더
시스템의 속성정보, 링커가 해당파일을 읽어서 분석할때 알아야하는 정보 저장 (전반적인 포맷정보)
text
컴파일된 프로그램 명령어의 기계어 코드
rodata
.rodata - 문자열,상수, switch등 읽기 전용값
data
.data - 0이 아닌 값으로 초기화되는 전역변수 및 static변수 저장
bss
.bss - 0으로 초기화 되거나 초기화 되지않는 전역변수 및 static 변수 저장
symtab
.symtab - 해당 모듈에서 정의하거나 참조하는 모든 변수들이 저장된다.
rel.text
.rel.text - 링킹시 필요한 .text 섹션 내 메모리 로케이션에 정보가 저장된다.
debug
.debug - 디버깅을 위한 정ㅈ보
line
원본 C 소스파일의 라인들과 .text섹션에 있는 기계어 코드들의 맵핑정보가 저장
strtab
심볼 이름들에 해당하는 문자열들과 섹션이름에 해당하는 문자열들이 저장된다.
섹션 헤더 테이블
각 섹션의 크기와 위치정보가 저장된다
컴파일러는 컴파일할때 각 심볼의 정보를 파악해 어셈블러에 전달하는데자기모듈에서 정의되는 전역심볼의경우 Strong심볼인지, Weak심볼인지 파악하여 재배치 가능 오브젝트 파일을 만들게된다. (상단에 말했듯 해당 모듈은 이게 어떤건지 알고있으며 모듈에 없는건 일단 UNDEF에 다 넣어둔다..)
추후 링커가 링킹을 수행하는 시점에서 심볼테이블에 각 전역심볼의 유형(Strong,Weak) 정보가 담겨있기에 이 시점에서 링커가 이를 바탕으로 전역심볼 중복문제를 처리한다.
리눅스의 경우 하단의 3가지 방식으로 중복문제를 처리한다.
동일한 이름의 Strong 심볼 여러개 -> 링커에러로 링킹종료
동일한 이름의 Strong + 동일한 이름의 Weak심볼 여러개 -> Strong 심볼 선택, Weak 심볼은 전부 삭제
동일한 이름의 Weak 심볼 여러개 -> 아무거나 선택 (만일 int x(A)와 char x(B)에서 개발자가 (A)를 선택함을 가정하에 49을 넣었으나 링커가 (B)에 49를 아스키코드로 판단해 1이 출력되는 문제 발생우려가 있다. 해당 문제는 컴파일상 사소한 문제일수도 있으나 실제 사용자 측면에선 큰에러로 발생할 우려가 있다 -> 선언시 초기화를 강조하는 이유)
오브젝트 파일의 .bss섹션에 넣어 표기하면 되지 않냐고 말할수도 있지만 어셈블러는 심볼테이블을 만드는 시점에서 해당 weak심볼이 링커에 선택될지 아닐지는 알수없기에 넣어둘수 없다.
따라서 어셈블러는 심볼테이블 엔트리에 COMMON센션으로 표기하고 나중에 링커는 COMMON 섹션으로 표기된 동명의 심볼을 따로 모아서 전역심볼중복문제를 처리한다.
(bss - 0으로 초기화 되거나 초기화 되지않는 전역변수 및 static 변수 저장)
중복문제를 해결할경우 각 심볼이 고유한 이름을 가지는걸 보장하므로 심볼정의를 심볼테이블에서 찾아 심볼해석을 진행할수있다.
컴파일 시스템은 연관된 여러 오브젝트 모듈을 단일의 LIB로 패키지화하는 기능을 제공한다. 이로인해 링킹을 수행할때 링커에 입력으로 들어가며실제로 프로그램이 참조하는 오브젝트 모듈만 실행 파일 안에 포함된다 (중복 없음)
정적 라이브러리(.LIB) - 실행파일과 링크를 걸면 static하게 실행 파일 내에 포함이 되는 라이브러리로 속도는 빠르지만 라이브러리에 변화가있을경우 이와 연관된 모든 실행파일은 수정된 버전으로 재링크 및 재컴파일이 필요하다.
만일 LIB가 없을경우 프로그래머는 3가지 방식으로 구현이 가능하다.
1. 컴파일러가 특정 함수에 대한 호출문을 발견하면 해당 함수의 코드를 직접 작성하는 방법 -> 컴파일중 함수가 없으면 새로 작성하고.. 하는 방식이나 컴파일러가 무거워진다.
2. 모든 표준함수들을 단일의 재배치 가능 오브젝트파일에 담아 공유 -> 1개의 파일에 함수를 전부넣은 헤더파일처럼 만들어 그때마다 입력하는 방식 (메모리 낭비가 너무 크고 파일에 수정사항이 생길때마다 전체를 재컴파일 해야한다.)
3. 각 표준 함수별 재배치 가능 오브젝트 파일을 만들고 이를 디렉토리에 저장하는 방식 -> 사칙연산 전용, 연속게삱 전용 등의실행파일을 만들때마다 필요한 함수의 모듈을 직접 찾아 입력으로 넣는 불편함이 있다.
그러나 LIB가 있다면 필요한 함수가 퐇마된라이브러리 파일의 이름만 커맨드라인에 적으면 프로그램이 실제로 참조한 심볼이 존재하는 모듈만 복사되기에 메모리 낭비를 막을수있다. (자주 사용되는 표준함수 등의 LIB는 컴파일러 드라이버가 자동으로 입력한다.)
재배치 (Relocation)
링커가 복수의 Object파일을 1개의 파일로 만들경우 각 코드에서 사용하는 변수, 함수는 개별 주소(상대주소)로 구성되있는데 이것을 링커가 재배치하여 주소(절대주소)를 바꿔주는것으로 하단의 2가지 순서를 거친다.
1. 섹션 및 섹션안에 존재하는 심볼정의를 재배치한다
동일 유형의 섹션들을 1개의 섹션으로 합쳐 실행파일에 담고 이것에 런타임 가상주소를 할당한다 -> 이 시점에서 모든 함수, 전역변수, Static변수는 고유한 런타임 가상주소를 갖는다 (런타임 - 프로그램 실행중)
2. 심볼 참조들을 재배치한다.
심볼정의들에게 부여한 가상 주소정보를 활용해 올바른 가상주소를 가리키도록 배치한다. 여기서 재배치 가능 오브젝트파일의 .rel.text섹션과 rel.data섹션에 담기는 재배치 엔트리들에 담긴다.
실행 가능 오브젝트 파일(좌측) 재배치 가능 오브젝트 파일(우측)
재배치 가능 오브젝트 파일과 유사한점을 찾을수 있는데 크게 다른점은 다음과 같다.
ELF 헤더 - 오브젝트 파일 전반적인 정보 저장, (Entry Point도 저장)
.text, rodata, data - 링커에 의해 최종적인 런타임 가상주소로 재배치
.init - _init이란 함수를 정의하며 이는 프로그램 초기화 코드에 호출되는 함수
이미 재배치가 완료된 온전한 실행파일이라 .rel.text, .rel.data섹션은 미존재
코드 세그먼트 - 읽기, 실행 권한이 부여된다
데이터 세그먼트 - 읽기, 쓰기 권한 부여
재배치 엔트리
어셈블러는 심볼정의가 무엇을 가리키는지 모르지만 가리키는 심볼정의의 최종적인 가상주소를 확정할수 없는 심볼참조를 만날때마다 재배치 엔트리를 만들어 재배치 가능 오브젝트에 담고 나중에 링커를 통해 심볼참조를 어찌 수정해야하는지에 대한 정보를 담는다.
즉, 어셈블러는 해당 심볼이 어떤것을 가리켜야 한다는건 알겠는데 최종적으론 뭘 가리키는건지 모를때 재배치 엔트리라는 리스트를 만들었다가 추후 링커를 통해 재배치를 받을 리스트를 확인하고 이를 링킹한다. - .rel data, .rel.text에 있는 재배치 엔트리를 가리킨다.
동적링킹과 정적링킹
정적링킹 (Static Linking)
실행가능한목적파일(응용프로그램)을 생성할때프로그램에서 사용하는 모든 라이브러리 모듈을 복사하는 방식 (동적링킹보단 빠른 속도를 보장)
변화를 반영하기 위해선 재 컴파일하여 재링킹이 필요하다 (기존 파일(A)를 복사(B)해서 프로그램을 만들어놨는데 (A)에서 변화가 생긴경우 (B)는 구버전이 되기에 오류가 생긴다)
본인이 작성한 프로그램(A),(B)에서 외부개체(Static Library 이하 "C"라고 표현)를 사용한경우 (A),(B)는 (C)의 모든 정보를 갖고있으며 중복이 발생될 우려가 있다. (각 프로그램마다 동일한 라이브러리를 차지한다는 의미이며 메모리 크기 커지는건 덤이다)
실행파일내 라이브러리 코드가 저장되기에 메모리 용량이 커진다. -> 이러한 단점으로 동적링킹이 등장하였다.
정적 링킹 프로그램에서 모든 코드는 한개의 실행모듈에 담기기에 불일치에 대한 우려가 없다. (각 프로그램마다 동일한 라이브러리를 복사하더라도 실질적으로 한개의 실행모듈이 실행하기에 불일치한건 없다
정적 라이브러리 (.LIB) - 컴파일시 링커는 프로그램이 필요로하는 부분만 찾아 실행파일에 복사 -> 실행파일에 라이브러리 자체가 들어있기에 라이브러리가 필요없고 컴파일도 이뤄져있기에 컴파일시간도 단축,
동적링킹 (Dynamic Linking)
런타임시 이뤄지는 공유 라이브러리의 동적링킹
실행가능한목적파일을 생성할때 프로그램에서 사용하는 라이브러리모듈의 주소만 갖고있다가 런타임으로 실행파일 및 라이브러리가 메모리에 적재될때 해당 주소에서필요한 모듈만 연결(링크)하는 방식 (위치만 알고있음)
기존 파일이 변경되어도 주소를 알고있기에 반영이 가능하다(단, 주소만을 갖고있기에 가볍지만 DLL이 없는경우 실행이 되다가 DLL이 필요한 시점에 파일이 없어서 에러가 나타날수 있다 -> 불일치에 대한 우려가 있다.)
정적링킹과 달리 필요할때마다 라이브러리에 접근해야 하기에 오버헤드가 발생할 여지가 있다.
메모리에 DLL파일이 없을경우 실행을 못하니 OS가 주소를 알고있다가 필요할때 메모리에 DLL파일을 올렸다가 사용이 끝나면 다시 내리는 방식 (자주 쓰이는 라이브러리는 메모리에 필요할때 가져오되 한개만 올리자.)
가끔 프로그램 실행할떄 ".DLL파일이 없습니다!"라고 출력되는데 주로 윈도우 시스템 디렉토리에 존재한다.
동적 라이브러리 (.dll) - 프로그램 실행시 실행 파일들과 연결하는 라이브러리 (프로그램이 실행될떄 필요할때만 DLL에 접근한뒤 다시 코드로 돌아오는 방식으로 실행 -> 컴파일후 실행파일과 독립되어있어 DLL파일의 위치를 실행파일에 설정한 공간에 위치시켜야한다.) OS에 의해 로드되면 물리메모리에 계속 남고 소스코드가 메모리에 올라갈때 DLL이 갖는 가상 메모리 주소와 매핑이된다.
구분
정적링킹
동적링킹
동작속도
빠름
느림 (접근시 오버헤드 발생)
수정사항 반영시 (재링킹 여부)
재컴파일 필요
재컴파일 필요X
자원 사용량
많음(복사했기에 용량이 큼)
적음(주소만 알기에 작음)
불일치에 대한 우려
X (중복시 미 복사)
O (있어도 일단 복사)
오버헤드
미발생
발생(주소로 접근하는시간)
메모리 요구사항
큼(전부 복사)
적음(필요시 복사)
로더
HW에 있는 실행 파일의 프로그램 헤더 테이블에 적힌 정보를 바탕으로 실행파일의 연속적인 바이트 정크를 코드 세그먼트와 데이터 세그먼트에 복사한뒤 이를 메모리에 적재, 실행하는 역할
컴파일 즉시 로더(Compile and Go) - 언어 번역 프로그램이 로더의 역할까지 담당하는 것으로 프로그램의 크기가 크고 한 가지 언어로만 프로그램을 작성할 수 있으나 실행을 원할 때마다 번역을 해야한다 -> 할당,재배치,적재 담당
절대 로더(Absolute Loader) - 단순히 목적프로그램을 입력받아 주기억장치의 적재만 담당하는 로더 -> 가장 간단한 로더이며 프로그래머가 지정한 주소에 적재할수 있으나 한번 지정한경우 위치변경이 어렵다
재배치 로더(Relocating Loader) -주기억 장치의 상태에 따라 목적프로그램을 주기억 장치의 임의의 공간에 적재할 수 있도록 하는 로더 - 4가지 기능 모두수행
링킹로더(Linking Loader) -하나의 프로그램이 변경되어도 다른 프로그램의 재 번역이 필요 없도록 프로그램에 대한 기억장소할당과 다른 프로그램의 연결을 로더가 자동으로 수행하는 프로그램 - 직접연결로더(DLL)
동적 적재(Dynamic Loading = Load on call) -모든 세그먼트를 주기억장치에 적재하지 않고 항상 필요한 부분만 주기억장치에 적재하고 나머지는 보조기억장치에 저장해두는 기법
주요기능 - 할당, 링킹, 재배치, 적재 -> 실행환경 초기화, main함수 호출 및 이에 대한 반환값 처리, 필요한경우 제어를 커널로 옮기는 역할도 수행)
조립컴퓨터 구매할때 window 프로그램 설치할거냐고 묻는데 만일 설치하지 않는다면 컴퓨터는 켜지기만 할뿐 우리가 생각하는 화면이 나타나지않는다.
이상태에서 컴퓨터를 사용하기 위해선 운영체제(OS)가 필요한데 이것에 대하여 조금 자세히 알아보자
운영체제 (OS, operating system)
HW가 컴퓨터 시스템 운영(조작)을 도와주는 SW로 window, mac, unix. linux 등이 있다(여러 SW가 프로그램을 실행할때 시스템적 조작을 애플리케이션에게 전가해주는 중재자, 자원할당자 역할)
OS 전체를 메모리에 적재하는건 무겁기도 하고 미사용하는 부분도 있기에 자원낭비를 초래한다.
이를 위하여 적재하는 OS를 2가지로 나누었는데 전원이 켜짐과 동시에 켜지는 메모리에 상시 상주하는 부분과(커널, Kernel)필요할때 마다 메모리에 적재시키는 부분으로 나뉜다.
커널에 적재하여 컴퓨터를 시작하는 과정을 시스템 부팅이라고 이야기한다.
시스템부팅 순서
1. 파워버튼 작동시 BIOS의 부트시스템, 부트로더가 커널위치를 찾아 시스템을 초기화시킨다. (컴퓨터 처음 가동소리가 나는시점)
몇몇의 컴퓨터는 다단계 부팅을 사용하며 전원이 켜질때 BIOS라 말하는 비휘발성 메모리(ROM)에 존재하는 부트스트랩이 부트로더를 실행
BIOS - OS중 가장 기본적인 SW로 컴퓨터 입출력을 담당하는 펌웨어이다.
펌웨어- HW에 저장된 SW로 OS에 권한을넘겨주기 전까지 컴퓨터를 제어하는것 (HW끼리 통신할때 통신이 무엇이고 이를 지시할 담당이 필요한데 이것을 펌웨어가 한다.)
부트스트랩 - 시스템 초기화 담당
2. 초기화 후 POST작업을 진행해 자체 검사후 메모리에 커널을 적재 (초기 검은화면)
부트로더 내부의 부트블록을 디스크에서 찾아 메모리에 적재하는 작업을 담당한다 - 하드웨어를 초기화하고 커널을 압축 해제 후 메모리에 적재, 제어를 OS에 넘기는 과정을 수행하는 것을 말한다. (여기서 펌웨어가 HW의 정상작동을 POST를 통해 확인한다
POST(Power on self test) - 부팅전 HW에서 자체적으로 진행하는 테스트
부트블록- OS 부팅에 필요한 코드를 저장되어있는 디스크영역
슈퍼블록- 블룩그룹의 가장 앞에 위치, 파일 시스템과 관련된 정보를 갖고있다(파일 시스템 전체크기, 마운트정보)
현재 대부분의 컴퓨터 시스템은BIOS를 UEFI로 대체하였다.
UEFI(Unified Extensible Firmware Interface) - BIOS(1980년대)보다 큰 디스크용량(2.1TB 이상 HW 인식)과 가독성이 좋은 GUI를 지원
3. 루트파일시스템 마운트된다.
루트파일시스템 - 파일 시스템의 최상위 디렉토리 (사진속 "/" 부분)
4. 컴퓨터 켜짐
컴퓨터 시스템 - 1개 이상의 CPU와 공유 메모리 사이의 액세스를 제공하는 공통 버스(BUS)를 통해 여러 장치 컨트롤러로 구성되며 각 장치의 컨트롤러마다 장치 드라이버를 필요로한다 -> 장치 드라이버(프린터 드라이버)는 장치 컨트롤러(프린터)의 작동을 담당하며 OS에게 장치 사용에 관한 인터페이스를 제공한다.
버스 - 컴퓨터 부품 또는 컴퓨터간 데이터와 정보를 전송하는 통신 시스템
컴퓨터 시스템은 각 장치 드라이브를 활용해 컴퓨터의 실행을 도와준다고 이야기했는데 각 장치 드라이버는 장치 컨트롤러를 적절한 레지스터에 적재하고 컨트롤러는 적재된 내용을 확인하여 작업을 실행한다.
만일 작업중에 더 급한(순위가높은)작업이 들어오면 컴퓨터 시스템은 인터럽트를 활용하여 자원의 재분배를 진행한다.
Mode Bit - CPU에서 실행되는게 OS인지, 사용자의 프로그램인지 구분하는 bit
인터럽트
특정 기능을 수행하던 도중에 어떠한 사유로(작업완료, 선순위 작업의 신규할당 등) 기존작업을 멈춰달라고 요청하는것 (장치드라이버가 컨트롤러에게, 하드웨어가 시스템 버스를 통해 CPU에게 전달)
시스템버스 - 컴퓨터 구성요소간 데이터 전송을 위해 필요로하는 통로
각 장치는 자신만의 인터럽트 매커니즘을 소유하며 장치간 구분을 위해 루틴의 주소값(인터럽트 벡터)를 인덱스로 사용한다. (이를 토대로 적절한 루틴을 거쳐 HW의 제어여부를 전달)
인터럽트 루틴은 인터럽트가 종료후 문제가 발생하기 이전상태로 복구를 진행하고 유일한 장치 번호로 색인된다.
그리고 인터럽트를 유발한 장치를 구분하기 위해 루틴의 주소값(인터럽트 벡터)을 인덱스값로 사용한다.
인터럽트 벡터 - 인터럽트를 처리할 서비스 루틴의 주소를 갖고있는 공간
인터럽트 서비스 루틴 - 인터럽트가 발생하면 어떻게 작업할지 정해진 OS내부의 코드로 인터럽트 종료시 이전상태로 복구(인터럽트 핸들러 라고도 한다)
인터럽트 서비스 - 인터럽트가 걸리고 처리하는 과정
인터럽트의 동작순서
1. 인터럽트 발생
2. 프로그램 실행중단
3. 현재 프로그램 상태 보존
4. 인터럽트 처리루틴 실행 - 원인 파악 및 실직적 작업 수행
5. 상태복구, 이전 작업 재실행
컴퓨터 시스템의 요소
1. HW - CPU, I/O장치(기본 계산용 자원)
2. OS
3. 응용프로그램 - 워드프로세서, 스프레드시트, 컴파일러
4. 사용자 - PC조작하는 사람
OS의 역할
1. 시스템 자원 관리자 (System Resource) - 운영체제가 없을경우 HW는 사용불가 (메모리, 파일시스템 ,프로세스, 캐시)
2. 사용자와 컴퓨터간 커뮤니케이션 지원 - I/O장치(키보드, 마우스 등)를 활용해 반응(클릭,입력)을 보이면 이것을 OS가 하드웨어로 연결해주는 역할
3. HW, 각종 프로그램 제어 - 프로그램의 실행, 실행권한, 사용자 관리
4. 보안 관리
5. 프로그램 수행
6. 보호 및 보안
시스템 자원(System resource) - 컴퓨터 HW(CPU, 메모리, I/O장치) 및 가상 구성요소
OS의 제공요소
1. 사용자 인터페이스 제공 (Shell - 사용자가 OS 및 서비스조작이 가능하도록 인터페이스 제공)
2. 응용프로그램을 위한 인터페이스 제공 - API, 시스템콜(시스템 호출 인터페이스 - API)
쉘(shell)
OS체재 내부(커널)과 사용자 사이의 인터페이스를 제공하는 프로그램으로 명령 줄셸(CLI 제공),그래픽 셸(GUI 제공)가 있다.
명령줄 인터페이스 (CLI, command-line interface) - 터미널을 통해 컴퓨터와 사용자가 상호작용하는 방식(명령 프롬프트)
그래픽 사용자 인터페이스 (GUI, graphical user interface) -사용자가 알기 쉽도록 표시해놓은 그래픽(인터넷 아이콘)
CLI (명령 프롬포트)
시스템콜 (System Calls) - 커널의 기능을 응용 프로그램 요청에 따라 커널에 접근하기 위한 인터페이스 (프로세스가 하드웨어에 직접 접근해서 필요기능을 사용 -> 보안을 위해 사용하며 "관리자의 권한으로 실행"을 생각하면 된다.)
프로그램 실행순서
1. 프로그램을 실행
2. 하드디스크에서 메모리로 저장 다음에 실행할 명령어를 주기억장치(CPU)로부터 읽는다 (Fetch)
2. 명령어를 디코드 한다 (Decode)
3. 피연산자(Operand)를 주기억장치로부터 읽어온다 (Operand)
4. 명렁어를 실행한다 (Execute)
운영체제의 기법과 정책
기법 (Mechanism) - 필요한 기능을 구현하는것 (어떤식으로 설계할지?)
정책 (Policy) - Mechanism 보다 상위의 정책으로 어떤종류의 결정을 내리는 알고리즘 (뭘 만들건지?)
타이머구조
CPU 보호를 위한 기법으로 특정 사용자(프로세스)를 위하여 타이머를 얼마간 설정할지 결정하는것
정해진 시간이 흐른뒤 OS에서 제어권이 넘어가도록 타이머 인터럽트를 발생시켜 CPU가 특정 프로그램이 독점하는것을 보호 (시분할 체제의 주요요건)
커널의 구조
커널 내부에 넣는 피쳐의 양에따라 모놀리식 커널(좌측), 마이크로 커널(우측) 2가지로 나뉠수 있다.
CPU는 주소값을 통하여 메모리를 접근하는데 메모리공간을 효율적으로 사용하기위해 적용되는 개념인 바인딩에 관하여 설명하겠다.
주소공간
하단의 사진은 주소값이 어떤식으로 배열되어있는지 나타낸 사진으로 메모리의 주소공간은 0번지부터 시작하며 0번지 주소의 대응하는 명령어는 0100 1111임을 확인할수 있다 또한 메모리의 단위는 byte로 이뤄진다.
레지스터는 CPU가 계산할 데이터는 램에 쌓여있는데 이것들은 CPU 안에서 연산되어야하기에 CPU 내부에 임시로 값을 저장할 공간이 필요하고 이 공간을 뜻한다.
레지스터 크기에 따라 32비트, 64비트로 구분된다. (윈도우의 32(x84),64비트는 레지스터의 크기가 2^32 또는 2^64임을 의미한다.)
주소 바인딩 (메모리 할당과정)
링커 (Linker) - 컴파일러가 원시코드를 파일로 생성하면 이 파일에 라이브러리와 다른 파일들을 결합 (exe 같은 파일을 생성시킴
로더 (Loader)-사용자 프로그램을 메모리에 적재시키는 프로그램 (지정 위치에서 시작해 메모리에 프로그램을 배치 -> 로딩을 해주는 역할)
프로그램이 실행을 위해 메모리에 적재되면(Symbolic Address) 그 프로세스를 위한 주소공간이 생성된다.
이것을논리적 주소(logical address) 또는 가상 주소(vritual addres)라고 칭한다.
논리적 주소는 각 프로세스마다 독립적으로 0번지부터 시작되며(가상주소 이므로 "여기서부터 0이다" 라고 선언하면 거기가 0이 된다고 이해하면 된다) CPU는 이 논리적 주소를 바탕으로 명령을 실행한다.
그리고 이 논리적 주소(가상주소)를 새로운 물리적 주소(실제 하드웨어)로 주소를 할당시키는것(Mapping)을 주소바인딩이라 표현한다. (가상에 임의로 부여했던 주소를 실제 메모리에 할당하며 이 작업은 Mapping은 MMU라는 메모리 관리장치가 담당한다.)
요약하자면 CPU가 기계어 명령을 수행하기 위해선
1. 프로그램이 물리적 메모리에 올라가야한다. (가상이 아닌 실제 메모리상의 주소값을 가져야한다)
2. CPU가 기계어 명령을 수행하기 위해선 논리적 주소를 통해 메모리를 참고하며 논리적 주소가 물리적 메모리에 매핑되어야한다.
물리적 주소 (Physical Memory Address) -> 실제 메모리
실제 하드웨어에 올라가는 주소로 물리적 메모리의 낮은주소(메모리가 낮다 -> 접근이 더 빠르며 이것이 우선 실행된다) 크기가 굉장히 큰 배열을 갖는다 생각하면 되며 각 배열을 구분하는 인덱스 값을 갖는데 이 값을 물리적 주소라고 이야기한다. (메모리 자체의 인덱스 (0x0001, 0x0002)를 의미)
모든 프로세스는 논리적 주소가 0번지부터 시작해서 차례대로 증가하기에 물리적 주소도 시작주소만 다르지 연속적으로 배치되어있다. (OS는 메모리를 최대한 활용하기 위해서 0부터(낮고 가져오기 쉬운 순서부터) 시작하고 이를 연속적으로 배치한다)
논리적 주소 (Logical Memory Address) -> 가상 메모리
동일한 공간을 공유할때 서로 침범하지 않기 위해선 사람들이 자신의 공간을 벽으로 나눴듯이 컴퓨터에서도 자신의 공간을 표시한것이 논리적 주소라고 생각하면 된다. (이것은 Base Register, Limit Register를 활용해 물리적 주소를 정한다)
논리적 주소는 CPU 입장에서의 메모리 주소로 프로그램이 실행중에 CPU가 생성하는 주소이다. (CPU가 실행시 실제 메모리가 아닌 가상에 할당하기에 가상주소라고 이야기 하기도 한다.)
프로그램이 1MB라면 0x00000 ~ 0xfffff (2^20 -> 1M)이다.
모든 프로세스는 논리적 주소가 0번지부터 시작해서 차례대로 증가하기에 물리적 주소도 시작주소만 다르지 연속적으로 배치되어있다.
OS는 메모리를 최대한 활용하기 위해서 0부터(낮고 가져오기 쉬운 순서 -> 주로 기본적인 프로그램들) 배치를 시작하고 이를 연속적으로 배치한다.
Symbolic Address
프로그래머들이 특정 이름을 통해 변수를 지정하고 값을 저장할때 이 변수를 하드웨어 어디에 저장할지 정하지 않는데 이것을 변수의 이름을 통하여 그 값에 접근하는것이며 이 변수를 Symbolic Address라고 칭한다
이 주소가 컴파일되어 숫자 주소가 만들어지고 이것이 물리적인 메모리와 매핑되는것이다. -> int a = 5; 에서 a의 주소
(여담으로 심볼릭 링크라는것도 있는데 이는 윈도우의 바로가기 아이콘이라고 생각하면 된다)
주소를 확정하는 방식
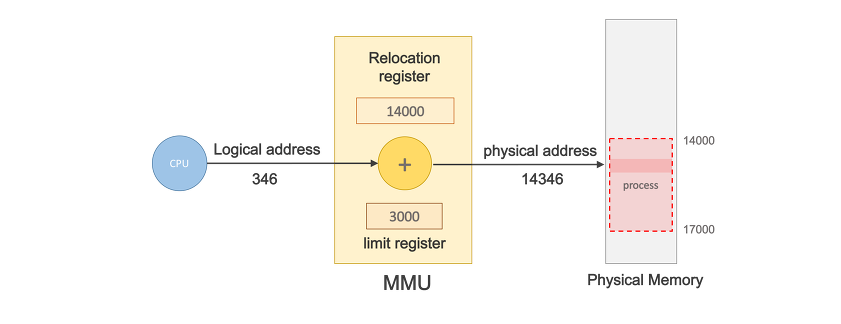
컴퓨터에선 이를 Base Register에 Limit Register 를 더하여 주소를 확정한다.
또한 한 프로세스의 모든 논리적 주소에 동일한 Base Register를 더하는 주소할당을"연속할당"이라고 표현한다.-> 연속적으로 나열된것 0x002가 끝인경우 다음 프로세스의 주소는 0x003이 되는것 (고정분할, 가변분할 2가지 방식이 있다)
불연속 할당
Base Register - 메모리(RAM)에 프로그램이 할당될때(논리적 주소) 프로그램의 시작주소를 의미한다. (재배치 레지스터라고 표현하기도 한다)
Limit Register - Base Register에서 현재 프로그램이 사용할수 있는 레지스터(논리적 주소)의 끝을 의미하며 CPU가 논리적 주소를 요청할 때 마다 한계 레지스터 값보다 작은 값인지를 검사 (논리적 주소에서 끝주소를 의미한다)
(Relocation Register와 Base Register는 동일한 것이라 생각하면 된다.)
Relocation Register - 접근할수 있는 물리적 메모리 주소의 최소(시작)값
조금 더 자세히 설명하면 상단 2개의 레지스터는 각 프로그램이 고유값으로 A프로세스의 논리적 주소는 Base Register + Limit Register로 Base Register가 0.00005이며 Limit Register가 10이면 A프로세스의 논리적 주소는 0.00005~0.00015까지 사용된다고 생각하면 된다.
만일 Limit Register가 10인데 주소를 0.00016까지 사용할경우 CPU는 trap(software interrupt)을 발생하고 프로그램을 에러를 뿜어내며 강제종료된다,
여기서 프로세스가 물리적 주소에 접근하려면 논리적 주소를 Mapping하는 과정이 필요한데 이것은 MMU(Memory Management Unit)가 이 역할을 수행한다.
주소 매핑 과정은 MMU가 하드웨어적으로 구현되어있으며 MMU는 논리적 주소에 Base Register값을 더해주면 된다.
프로세스(Process) - 컴퓨터 내에서 프로그램을 수행하는 컴퓨터에서 실행하는 하드웨어 유닛으로 1개 이상의 ALU 및 처리 레지스터 내장 (특정 목적을 수행하기 위해 메모리에 적재되어 프로세서에 의해 실행중인 프로그램(작업목록))
프로세서(Processor) -> 명령어를 해석하는 컴퓨터의 한부분으로 데이터 포맷을 변환하는 역할을 수행하는 프로세싱 시스템 (데이터 처리 시스템)을 의미하며 인쇄물을 출력하는 워드프로세서도 프로세서라 불리운다. (CPU, 어셈블러 등)
MMU기법 (MMU scheme)
MMU는 CPU가 논리적 주소를 참조하고 싶을때 그 주소값에 기준 레지스터값(base register)을 더해 물리적 주소값을 얻어낸다 (주소를 유추하고 싶을때는 MMU 논리적 주소에 base 레지스터값을 더해주면 된다)
기준레지스터(Relocation Register)는 재배치 레지스터라고 표현하기도 하며 프로세스의 물리적 메모리 시작주소(를 갖고있다.
MMU는 프로그램 주소공간이 연속적으로 적재되있음을 가정하에 진행한다.
멀티 프로세싱을 위해 가상주소를 사용한다.
논리적 주소를 물리적 주소로 매핑해주는 하드웨어 디바이스
CPU가 프로세스의 논리적주소와 기준 레지스터의 값을 더하여 물리적 주소 값을 얻는다 -> 이것은 곧 물리적 주소의 시작주소만 알아낸다면 주소변환이 가능하다는 의미이다.
마이크로 프로세서(microprocessor) - 기계어 코드를실행하기 위해 실행과정을 단계적으로 나누어 처리를 위한 마이크로 코드를 작성하고 이것을 단계적으로 처리하는 논리회로
MMU scheme - 사용자 프로세스가 CPU에서 수행되며 생성해내는 모든 주소값에 대해 Base Register의 값을 더해준다.
user program - Logical address만 다루며 실제 물리적 주소를 볼수 없다.
주소의 매핑은
Relocation Register과 base Register는 같은 것으로 생각하면 된다?
(주소 매핑 과정은 빈번하게 이뤄지므로 MMU는 하드웨어적으로 구성되어있다)
여기서 굳이 Mapping하지말고 물리적 주소만 쓰면 속도가 더 빠르지 않냐는 궁금증이 생기는데 만일 논리적 주소를 사용하지 않고 물리적 주소 그러니까 실제 HW의 주소만 사용하면 같은 프로그램이 존재할때 한개의 프로그램은 실행되지 않는다 (크롬 여러창을 띄울수 없다고 생각하면 된다 -> 게임 클라이언트가 실행중인데 또 실행하면 이미 실행중이기에 다른 클라이언트가 안켜진다)
반면 논리적 주소는 컴파일할때 주소가 확정되는것이 아닌 실제 프로그램을 실행시킬때 메모리 빈공간에 논리적 주소(가상주소)를 만들고 물리적 주소와 같이 바인딩 하기에 물리적 주소가 같은 프로그램을 여러개 띄울수 있는것이다.
여기서 바인딩은 어느시점에서 논리적주소(가상주소)가 물리적주소(실제주소)로 언제 Mapping할것이가? 궁금증이 생길것이다.
바인딩의 방식은 물리적 메모리의 주소가 결정되는 시점에 따라 컴파일 타임 바인딩,로드 타임 바인딩, 실행시간 바인딩 3종류로 구분된다.
컴파일 타임 바인딩(Compile time binding)
프로그램을 컴파일할때 물리적 메모리 주소가 결정되는 방식 (프로그램 전체가 메모리에 올라가야한다)
즉, 처음부터 프로그램 내부에서 사용하는 주소(논리적 주소)와 물리적 메모리 주소가 동일
물리적 메모리 위치 변경을 하려면 재컴파일을 사용하며 기점유 하고있는 프로세스가 있는경우도 있다.
하나의 프로세스만 사용할때 사용하며 현재 범용적으로 사용중인 멀티 프로세싱에 부적합한 로드방법이다.
(이미 실제 메모리에 사용중인 크롬A의 주소가 있는데 크롬B를 그 사이에 호출하고 주소를 넣을순 없다 -> 우리는 앞서 메모리는 연속적으로 나열된다고 했는데 컴파일 타임 바인딩은 실행시점만 주소에 값을 넣을수 있기에 추가적인 실행은 불가능하다.)
로드 타임 바인딩(Load time binding)
프로그램 시작시(메모리에 로드,적재될때) 물리적 메모리 주소가 결정되며 로더의 책임하에 물리적 메모리 주소가 부여되며 프로그램이 종료될 때까지 물리적 메모리상의 위치 고정
초기에 부여되는 논리적 주소와 물리적 주소가 다르기때문에 멀티 프로세싱 환경에 용이하다 (물리적 메모리 주소와 논리적 메모리 주소를 분리하여 처음엔 가상주소로 들고있다가 프로그램 실행시 물리적 주소로 변경, 프로그램 종료전까지 물리적 메모리상의 위치가 고정)
프로그램 내부에서 사용하는 주소(논리적 주소)와 물리적 메모리 주소는 다른방식이다.
메모리를 참조하는 명령어를 다 변경해야하는 단점으로 메모리 로딩시간이 엄청 오래걸리는 단점으로 잘 사용되진 않는다.
실행시간 바인딩 (execution time binding 또는 run time binding)
프로그램 실행 이후로 프로그램이위치한 물리적 메모리상의 주소의 변경이 가능한 바인딩방식 (실시간 물리적 주소의 변경을 의미하며 이것은 프로세스가 메모리에 연속적(Continuous)으로 적재된것을 가정하에 진행한다)
CPU가 주소를 참조할때마다 해당 데이터의 물리적 메모리가 어디에 있어야하는지 주소매핑테이블(address mapping table)을 통해 바인딩을 점검한다.
실행시간에 바인딩이 이뤄지기에 기준 레지스터(Base Register)와 한계 레지스터(Limit Register)를 포함한 MMU라는 하드웨어적인 자원이 필요하다
동적적재 (Dynamic Loading)
디스크에 프로그램을 여러 루틴(Function)으로 나눠 저장
해당 루틴이 실제 호출되기 전까지는 루틴을 메모리에 미적재, 메인 프로그램만 메모리에 적재하여 수행
루틴이 호출되면 바인딩 수행
미사용할 루틴은 메모리에 미적재하여 메모리의 효율적 사용이 가능
요약
1. 프로세스는 논리적 주소(가상주소)에 배치된다.
2. 논리적 주소를 물리적 주소(실제 하드웨어 주소)로 변환하는걸 바인딩이라 한다
3. 바인딩은 Base Register + Limit Register를 통해 주소값을 확정짓는다.
제네릭이란 데이터의 타입을 일반화(generalize) 하는것을 의미하며 클래스 및 메서드에서 사용할 내부 데이터 타입을 컴파일시에 미리 지정하는것을 의미한다.
조금더 상세하게 설명하면 1개의 값이 여러 타입의 데이터를 갖도록 하는 방법이다
우리가 메뉴판 프로그램을 만든다고 하면 이를 사용하는 가게주인은 가격란에 30,000을 입력할수도, 삼만원을 입력할수도 있는고 만일 데이터 타입을 int나 String 으로 정한다면 둘 중의 1개는 무조건 버그가 나타날것이다.
이런식이다..
이런 문제를 해결하기 위해 제네릭이 사용되며 처음 작성할때는 어떤타입이든 올수 있도록 해놨다가 값(파라미터)를 넣을때 데이터의 형식을 정해주는게 사용하는게 제네릭이다.
제네릭을 사용하는 이유
1. 컴파일시 강한 타입체크이 가능하다.
2. 타입변환(Casting)을 제거
이것을 하단의 코드와 함께 설명하겠다.
class Studentinfo{
public int grade;
Studentinfo(int rank) { this.rank = rank; }
}
class Employeeinfo{
public int rank;
Employeeinfo(int rank) { this.rank = rank; }
}
class Person{ //(A)
//Objcet타입은 추상적인 타입으로 어떤 타입이든 들어갈수 있다.
public Object info; //int, char등 모든 타입이 들어갈수 있다
Person(Object info) { this.info = info; }
}
public class test { //(B)
public static void main(String[] args) {
Person p1 = new Person("개발자"); //Object형으로 되어있다.
//Object가 최상위인건 알겠는데 지금 사용하려는게 어떤타입(int?String?)이냐?...
Employeeinfo ei = (Employeeinfo) p1.info;
System.out.println(ei.rank);
}
}
여기서 (A)를 본다면 Object로 선언되있는데 Object는 각 파라미터 타입의 최상위객체이므로 어떤 타입(int,String,float...)을 넣어도 문제가 없게 만든다. -> 이것을 "타입이 불안전하다"고 표현한다.
(컴파일 단계에선 (문법적)에러가 없으나 코드의 원래목적과 다른 결과값이 나오기때문이다.)
이것은 (B)처럼 int값이 들어갈 부분인데 String값이 들어가도 문법상 오류는 없어 컴파일러는 캐치할수 없기에 찾기 어려운 버그가 생기게 되는것이다. (치킨 가격에 "15000"이 출력되야 하는데 "국내산 닭" 이라고 출력되는 버그..)
이것을 제네릭방식으로 바꾼 코드를 보겠다. (제네릭 예시 코드 참조)
//제네릭 예시
class EmployeeInfo{
public int rank;
EmployeeInfo(int rank) { this.rank = rank; }
}
//T와S는 와일드 카드이다
//제네릭에서 복수의 파라미터를 받는경우 앞부분(T)은 참조 데이터타입만 가능
//복수의 파라미터를 받는경우 뒷부분(S)는 기본데이터 타입인 Integer, Char만 올수있다.
class Person<T, S>{ //멀티타입 파라미터
public T info;
public S id;
Person(T info,s id) {
this.info = info;
this.id = id;
}
}
public class test2 {
public static void main(String[] args) {
Integer id = new Integer(1);
Person<EmployeeInfo, Integer> p1 = new person<EmployeeInfo, Integer>(new EmployeeInfo(1), id);
System.out.println(p1.id.intValue()); //레퍼클래스에서 갖고있는 숫자를 int타입숫자1로 형변환
}
}
//제네릭은 상속과 구현도 가능하다.
//부모클래스,자식클래스가 될수있다.
public class 자식클래스명<T,M> extends 부모클래스<T,M> {...}
//파라미터의 추가도 가능하다.
public class 자식클래스명<T,M,C> extends 부모클래스<T,M> {...}
(와일드카드 - 어떤값이든 올수 있다는 의미로 여기서는 T나 S에 int, String등 어떤타입이든 올수있음을 의미한다)
상단의 코드를 어느정도 이해했다면 하단의 코드를 살펴보자
여기서 제네릭 타입은 타입(int,String)을 파라미터로 갖는 클래스와 인터페이스를 뜻한다.
//class<T>, interface<T> -> <>제네릭 의미, T -> 파라미터의 타입을 의미
//제네릭타입 기본적인 양식
public class test1<Sting> { ... } //string형 제네릭 클래스
public class test2<Integer> { ... } //int형 제네릭 클래스
public interface test3<T>{ ... } //타입 파라미터의 이름은 T이며 제네릭 인터페이스
//CASE A
List<String> list = new ArrayList<String>(); //String만 받도록 생성
list.add("help"); //리스트에 글자삽입
String a = list.get(0); //String으로의 타입변환 없이 출력됨
//CASE B
List list = new ArrayList();
list.add("hello");
String b = (String)list.get(0) //String으로 Casting 필요
CASE A는 제네릭을 활용하여 캐스팅이 필요없는 코드이고
CASE B는 제네릭 없이 사용한 일반적인 코드이다.
B에 대하여 설명하자면 이전의 포스팅에서 우리는 자료형을 선언할때 아무런 조치를 하지 않는경우 JVM에서 Object를상속받는다 이야기했는데 여기서도 이개념이 동일하게 적용된다.
List를 저장할때 앞에 자료형선언이 없었기에 Object를 상속받았는데 Object는 최상위클래스지만 위에서 이야기한 Object는 타입이 불안전한 이유로 인하여 Casting을 진행한 이유다.
추가로 제네릭 타입은 static변수를 사용할수 없는데 이것은 클래스가 인스턴스가 되기전 static은 메모리에 먼저 올라감과 동시에 T의 타입이 정해지는데 이때 T는 타입이 결정되지 않았기때문에 에러가 나타난다. (후술할 제네릭 메서드에서 부연설명 예정)
멀티타입 파라미터
//제네릭에서 복수의 파라미터를 받는경우 앞부분(T)은 참조 데이터타입만 가능
//복수의 파라미터를 받는경우 뒷부분(S)는 기본데이터 타입인 Integer, Char만 올수있다.
class Person<T, S>{ //T,S는 임의로 붙인 이름
public T info;
public S id;
Person(T info,s id) {
this.info = info;
this.id = id;
}
}
public class test2 {
public static void main(String[] args) {
Integer id = new Integer(1);
Person<EmployeeInfo, Integer> p1 = new person<EmployeeInfo, Integer>(new EmployeeInfo(1), id);
//자바7 이상은 타입 파라미터 부분을 유추하여 자동으로 설정해준다. (코드양이 줄었다!)
//Person<EmployeeInfo, Integer> p1 = new person<>(new EmployeeInfo(1), id);
System.out.println(p1.id.intValue()); //레퍼클래스에서 갖고있는 숫자를 int타입숫자1로 형변환
}
}
해당 코드는 상단의 코드를 가져온것으로 복수의 파라미터를 사용할수 있는데 각 파라미터(T,S)를 콤마로 구분한다.
제네릭메서드
제네릭메서드는 매개타입, 리턴타입으로 타입(int,string)파라미터를 갖는 메서드를 의미한다.
상단에서 제네릭 타입은 static이 사용 불가능하다고 이야기했지만 제네릭 메서드는 static의 사용이 가능하다
그 이유는 static이 갖는 특징과 타입이 결정되는 시점을 생각하면 된다.
제네릭 타입은 인스턴스가 생성될때 타입이 결정된다 ( 인스턴스 생성 예시로 "cat = new Animal()" 에서 Animal에 들어가는 데이터 타입(int,String)에 따라 제네릭타입이 갖는 타입(int,String)이 정해진다.)
그에 반해 static은 인스턴스 생성과 별도로 이미 메모리에 올라가있다. (어떤타입인진 몰라도 Object형으로 이미 올라가있어 제네릭타입을 사용이 불가능한것이다.)
즉, static으로 선언된 메서드는 인스턴스가 생성되는 시점에 결정되는 제네릭 타입을 매개변수로 받을수 없는데 반해
제네릭 메서드는 생성과 별도로 메모리에 올라가있는데 제네릭으로 시그니처된 메서드는 호출된 시점에 타입이 결정되기 때문에 에러가 발생하지 않는다 (메서드를 호출시 여기에 들어갈 값(파라미터)가 정해지거나 값이 넣어진 상태로 호출되기 때문에 static을 사용해도 문제없다)
제한된 타입 파라미터 (T extends 최상위타입)
public <T extends 상위타입> 리턴타입 메서드(매개변수, ...) { ... }
타입파라미터에서 구체적인 타입을 제한할 필요가 종종 있다.(숫자만 들어가는경우 int,float의 상위타입인 Number타입만 가능하도록 지정 (EX : 가격표))
이것을 제한된 타입 파라미터(bounded type parameter)라고 표현한다.
//제한된 타입 파라미터 예시
public <T extends 상위타입> 리턴타입 메서드명(매개변수,...) { ... }
//사용예시 (A)
public class Util {
public <T extends Number> int compare(T t1, T t2) {
double v1 = t1.doubleValue(); //Number의 하위타입은 double로 변형
double v2 = t2.doubleValue();
return Double.campare(v1,v2);
//compare() => 좌우가 동일할경우 = 0, 좌측크면 1, 우측이 크면 -1
}
}
//사용예시
public class BoundedTypeParameterExample {
public static void main(String[] args) {
//타입 파라미터로 배열을 생성하려면 "(T[]) (new Object[n])"형태로 생성한다.
//String str = Util.compare("a","b");
//"a","b"는 Number의 하위타입이 아니기에 에러가 출력된다
int result1 = Util.compare(10,20); //20은 int형에서 Integer 형으로 Boxing된다.
System.out.println(result1); //-1 출력
int result2 = Util.compare(4.5,3); //4.5는 double형에서 Double 형으로 Boxing된다.
System.out.println(result2); //1 출력
}
}
(int형과 Integer의 차이점)
int는 변수의 타입(data type)을 의미한다. (변수는 값을 저장할수 있는 메모리상의 공간을 의미하며 4바이트를 의미한다.)
동영상 플레이어 실행 중 영상의 일시정지, 음소거, 자막삽입등 우리가 사용하는 프로그램에선 여러가지 기능(스레드)을 활용하는데 이것을 조정하는게 스레드 상태제어라고 이야기한다.
상태제어의 흐름도와 대표적으로 사용되는 메서드는 다음과 같다
스레드 흐름도 (밑줄친건 가급적 사용하지 말라)
상태제어 메서드
메소드
설명
interrupt()
일시 정지 상태의 스레드에서 InterruptedException 예외를 발생시켜, 예외 처리 코드(catch)에서 실행 대기 상태로 가거나 종료 상태로 갈 수 있도록 한다.
notify() norifyAll()
동기화 블록 내에서 wait() 메소드에 의해 일시 정지 상태에 있는 스레드를 실행 대기 상태로 만든다.
resume()
suspend() 메소드에 의해 일시 정지 상태에 있는 스레드를 실행 대기 상태로 만든다. - Deprecated(대신 notify(), notifyAll() 사용)
sleep(long millis) sleep(long millis, int nanos)
주어진 시간 동안 스레드를 일시 정지 상태로 만든다. 주어진 시간이 지나면 자동적으로 실행 대기 상태가 된다.
join() join(long millis) join(long millis, int nanos)
join() 메소드를 호출한 스레드는 일시 정지 상태가 된다. 실행 대기 상태로 가려면, join() 메소드를 멤버로 가지는 스레드가 종료되거나, 매개값으로 주어진 시간이 지나야 한다.
wait() wait(long millis) wait(long millism, int nanos)
동기화(Synchronized) 블록 내에서 스레드를 일시 정지 상태로 만든다. 매개값으로 주어진 시간이 지나면 자동적으로 실행 상태가 된다. 시간이 주어지지 않으면 notify(), notifyAll() 메소드에 의해 실행 대기 상태로 갈 수 있다.
suspend()
스레드를 일시 정지 상태로 만든다. resume() 메소드를 호출하면 다시 실행 대기 상태가 된다. - Deprecated(대신 wait() 사용)
yield()
실행중에 우선순위가 동일한 다른 스레드에게 실행을 양보하고 실행 대기 상태가 된다.
stop()
스레드를 즉시 종료시킨다. - Depecated (가능한 쓰지말것)
sleep() - 일정시간동안 정지(시간 경과시 실행대기상태)
주어진 시간동안 일시정지, 시간 경과시 실행대기로 변환
Thread.sleep(1000); //sleep의 단위는 밀리세컨드(1/1000)이다.
yield() - 우선순위가 같거나 높은 스레드에게 실행양보(호출한 스레드가 실행대기상태)
실행한 스레드는 실행대기가 되며 자신보다 우선, 동일한 순위의 스레드에게 실행을 양보한다
반복적인 작업(for,while)을 하는경우 이것이 진행중임을 확인하기위해 일정한 코드를 넣어 확인하는 경우가 있는데 (우리가 핸드폰을 터치중일경우 핸드폰은 하루종일 터치받는 신호를 1밀리초마다 받고있는것이다) 이것이 언제 종료될것인지 정해주지 않는다면 계속 무의미한 반복(메모리 낭비)을 하게되는데 이런낭비를 다른곳으로 돌려쓰기위한 메서드가 yield()이다.
Thread.yield();
join() - 다른 스레드의 종료를 기다림
스레드의 우선순위를 정했지만 선행되야할 스레드를 무시한채 후순위 스레드부터 시작하는경우 예상과 다른 결과가 출력된다. 이러한 문제를 해결하기 위해 사용하는것이 join()메서드이다.
두개 이상의 스레드를 교대로 번갈아가며 실행할경우 사용하며 호출한 스레드는 실행대기상태로 된다.
(캐릭터 2~3개 또는 A,B모드를 한번에 조종한다고 생각하면 이해할것이다)
wait를 사용하기 위해선 공유객체는 두 스레드가 작업할 내용을 각각 동기화 메서드(Synchronized Method)로 구분한뒤 한 스레드가 작업을 완료한경우 notify()를 호출하여 일시정지 상태에 있는 다른 스레드를 실행대기 상태로 만들고 자신은 wait()를 호출하여 일시정지로 만든다.
wait()에 값을 넣는경우 notify()를 호출하지 않아도 값(시간)이 지나면 자동적으로 실행대기 상태가 된다.
//일시정지 = wait()호출, 일시정지 -> 실행대기로 변경 - notify()호출
//초기
A - 실행대기
B - 실행대기
//A실행
A - 실행중
B - 실행대기
//A 종료 및 B 실행
A - 일시정지 (wait())
B - 실행대기 -> 실행
//B 종료 A 실행
A - 일시정지 -> 실행대기 -> 실행 (notify())
B - 일시정지 (wait())
스레드 종료 - Stop플래그, interrupt()
run 메서드가 모두 실행되면 종료되는데 이것이 비정상적으로 종료되는경우 기존에 사용되던 자원은 환원되지 못하고 계속 메모리를 차지하고 있게되는 불상사가 있다.
(다운로드중 인터넷이 끊기면 파일이 fdsragds.434.fds이런 형식으로 남는다)
Stop 플래그
stop 플래그 방식은 조건식에 stop를 넣어서 false인경우 자원반환 코드를 넣는방식이다.
public void run() {
while(!stop){ 반복할 코드 }
스레드가 사용한 자원 정리 코드
}
}
interrupt()
스레드가 일시정지 상태에 있을때 interruptedException예외를 발생시키는 역할로 해당 에러가 발생했을때 run메서드의 정상종료를 꾀할수 있다. (일시정지가 아닌 실행,실행대기 상태에서 interrupt() 사용시 예외가 발생하지 않고 이후에 일시정지 상태가 되어야 예외가 발생한다.)
interrupt가 정상적으로 작동된경우 true를 리턴하는데 이것을 이용하여
Thread.interrupt(); //interruptedException예외발생
데몬스레드(daemon)
주 스레드의 작업을 돕는 보조적인 스레드로 주 스레드 종료시 보조 스레드(데몬스레드)도 종료된다. (종속된다고 생각하면 된다)
주스레드 : 워드, 영상 플레이어, JVM
보조 스레드 : 워드의 자동저장, 동영상 및 음악재생, GC
단, start() 메서드 호출한뒤 setDaemon(true)를 호출하면 ILLEGAlThreadStateException발생
ILLEGAlThreadStateException - 쓰레드 에서 Start로 작업중인데 Start를 한번 더 실행한경우 ("이미 실행중인데 또 실행하라고?")
또한 스레드 그룹에서 제공하는 여러 메서드가 있는데 한가지 예시로 interrupt()메서드를 호출하면 스레드 전체의 제어 및 정보를 얻어올수 있기 때문이다.
(스레드 그룹의 interrupt() 메서드 호출시 각 스레드마다 interrupt() 메서드를 내부적으로 호출해준다.)
interrupt - 스레드에게 작업을 멈춰달라고 요청하는것
여담으로 JVM은 실행될때 system이름의 스레드 그룹을 생성하고 JVM이 운영에 필요한 스레드를 생성하여 system그룹에 포함시킨다. (Finalizer(GC관련 스레드)가 있다.)
스레드그룹이 갖고있는 주요 메서드
코드
설명
(int형) activeCount()
현재 또는 하위그룹에서 활동중인 모든 스레드의 수를 리턴
(int형) activeGroupCount()
현재 그룹에서 활동중인 모든 하위그룹의 수를 리턴
(int형) getMaxPriority()
현재 그룹에 속한 스레드가 가질수 있는 최대 우선순위를 리턴
(bool형) isDestoryed()
현재 그룹이 삭제되었는지 여부를 리턴
(bool형) isDaemon()
현재 그룹이 데몬그룹(보조그룹)인지 여부를 리턴
(bool형) parentOf(ThreadGroup g)
현재 그룹이 매개값으로 지정한 스레드 그룹의 부모인지 여부를 리턴
(void형) checkAccess()
스레드가 스레드 그룹을 변경할 권한여부 체크(관리자인지?) 권한이 없으면 SecurityException을 발생
(void형) destory()
현재 및 하위그룹을 모두 삭제 (그룹내에 포함된 스레드가 종료상태가 되는게 전제조건)
(void형) setMaxPriority(int pri)
현재 그룹에 속한 스레드가 가질수 있는 최대 우선순위를 설정
(void형) setDaemon(boolean daemon)
현재 그룹을 데몬그룹(보조그룹)으로 설정한다
(void형) list()
현재 그룹에 포함된 스레드와 하위그룹에 대한 정보를 출력
(void형) interrupt()
현재 그룹에 포함된 모든 스레드를 interrupt()한다.
(String형)getName()
현재 그룹의 이름을 리턴
(ThreadGroup형)getParent()
현재그룹의 부모그룹을 리턴한다.
스레드 그룹 생성
자신이 원하는 스레드 그룹을 만들어 관리하고 싶다면 하단의 코드를 활용하여 스레드 그룹을 생성하면 된다.
//parent - 부모로 만들 스레드그룹 이름
//name - 생성할 스레드그룹 이름 작성
ThreadGroup tg = new ThreadGroup(String name); //메인스레드에서 생성시 main의 하위스레ㅡ
ThreadGroup tg = new ThreadGroup(ThreadGroup parent, String name);
//스레드 그룹을 매개값으로 Thread 생성자
//target - Runnable 타입 구현객체
//name - 생성할 스레드의 이름
//stackSize - JVM이 할당할 stack의 크기
Thread t = new Thread(ThreadGroup group, Runnable targer);
Thread t = new Thread(ThreadGroup group, Runnable targer, String name);
Thread t = new Thread(ThreadGroup group, Runnable targer, String name, long stackSzie);
Thread t = new Thread(ThreadGroup group, String name);
모든 스레드는 반드시 하나의 스레드 그룹에 포함되며 명시적으로 스레드 그룹에 포함시키지 않으면 자신을 생성한 스레드 그룹에 속하게된다.(디폴트)
EX : 우리가 생성하는 작업스레드는 대부분 main스레드가 생성한다(main 스레드 그룹에 속한다)
또한 현재 사용중인 스레드 그룹의 이름을 확인하려면 다음과 같은 코드를 작성한다.
//현재 스레드가 속한 스레드그룹의 이름
ThreadGroup group = new Thread.currentThread().getThreadGroup();
String a = group.getName();
//프로세스내에서 실행하는 모든 스레드의 대한 정보 (그룹명, 소속그룹)
스레드 그룹 예시 코드
//자동 저장용 코드
public class AutoSaveThread extends Thread {
public void save(){ //메서드 생성
System.out.println("저장완료");
}
@Override
public void run(){
while(true){ //무한반복
try{
Thread.sleep(1000); //1000밀리초 = 1초 딜레이
} catch (InterruptedException e) {
break; //while 탈출
}
save(); //상단의 save 호출
}
}
}
스레드 그룹 예시코드 2
//스레드 정보 얻기 코드
public class ThreadInfoExample {
public static void main(String[] args) {
AutoSaveThread autoSaveThread = new AutoSaveThread(); //스레드 생성자
autoSaveThread.setName("AutoSaveThread"); //스레드명 변경
autoSaveThread.setDaemon(true); //데몬(보조)스레드 선언
autoSaveThread.start();
//autoSaveThread.isDaemon(); //autoSaveThread 데몬스레드인지 확인용 (true 리턴)
Map<Thread. StackTraceElement[]> map = Thread.getAllStackTraces();
Set<Thread> threads = map.keySet();
for(Thread thread : threads) { //Thread 전체 루핑
System.out.println("Name: " + thread.getName() +
((thread.isDaemon())?"(데몬)": "(주)"));
System.out.println("\t" + "소속그룹: " + thread.getThreadGroup().getName());
System.out.println();
}
}
}
(루핑 - 요소 전체를 반복하라)
스레드 풀
멀티스레드, 병렬작업이 많아질수록 스레드 증가, 이에 따른 스케쥴링으로 메모리 사용량이 늘어나는데 이를 내버려뒀다간 스레드 폭증으로 PC가 뻗어버리게된다.
이를 막기 위해선 스레드풀이란 기능을 활용해야한다.
스레드풀 - 작업 처리에 사용되는 스레드를 제한된 개수만큼 정해놓고 작업 큐(대기열)에 들어오는 작업을 하나씩 스레드가 처리한후 작업처리가 끝난 스레드는 다시 작업 큐(대기열)에 들어오는작업을 가져와 처리한다.
(손님이 들어오는대로 다 받으면 식당 내부에서 난리가 날테니 줄세워놓고 한명씩 들어오라 하는것)
자바는 스레드풀 생성을 위하여 java.util.concurrent 패키지에 ExecutorService인터페이스 및 Executor 클래스를 제공한다
스레드풀 생성
ExecutorService 구현객체는 Executor 클래스의 여러메서드중 하단의 양식을 사용하여 생성한다.
//스레드풀 생성 1번
//양식 : newCachedThreadPool()
//초기 스레드 및 코어스레드 : 0개, 최대스레드 : interger.MAX_VALUE
ExecutorService executorService = Executors.newCachedThreadPool();
//스레드풀 생성 2번
//양식 : newFixedThreadPool(int nThreads)
//초기 스레드 : 0개, 코어스레드 : nThreads개, 최대스레드 : nThreads
ExecutorService executorService = Executors.newFixedThreadPool(
Runtime.getRuntime().availableProcessors() //JVM에서 현재 이용가능한 코어갯수를 리턴
//CMD사용하기 - Runtime.getRuntime()
//JVM에서 현재 이용가능한 코어갯수를 리턴 - availableProcessors()
)
//스레드풀 생성 3번 (Executor 클래스 미사용시)
//초기스레드는 0개이다.
//ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue)
ExecutorService threadPool = new ThreadPoolExecutor(
3, //코어 스레드 개수 -> corePoolSize(생성할 개수)
100, //최대 스레드 개수 -> maximumPoolSize(생성할 최대 개수)
120L, //놀고있는 시간으로 초과시 삭제 -> keepAliveTime(유지 시간)
TimeUnit.SECONDS, //놀고있는 시간단위 (초) -> TimeUnit unit
new SyschronousQueue<Runnable>() //작업 큐 -> BlockingQueue<Runnable> workQueue
);
스레드가 작업처리를 완료하고 외부 Result객체에 작업결과를 저장하면 애플리케이션이 이것을 활용해 작업이 가능하다.
class Task implements Runnable {
Result result; //외부 객체 사용을 위해 선언
Task(Result result) { this.result = result; } //외부 Result 객체를 필드에 저장
@Override
public void run() {
//작업코드
//처리 결과를 result에 저장
}
}
작업완료순으로 통보
작업을 요청한 순서대로 작업처리가 완료되는건 아니며 드문드문 완료된 스레드를 찾는 작업은 CompletionService의 poll(), take()메서드를 사용한다
리턴타입
메서드명(매개변수)
설명
Future<V>
poll()
완료된 작업의 Future를 가져옴 완료된 작업이 없을경우 null리턴
Future<V>
poll(long timeout, TimeUnit unit)
완료된 작업의 Future를 가져옴 완료된 작업이 없을경우 timeout까지 블로킹후 그래도 없으면 null 리턴
main스레드의 첫 코드부터 아래로 순차적으로 실행하며 코드 중간에 외부에 있는 스레드가 있을경우 그것을 중간에 실행한뒤 메인스레드로 넘어오는 방식이다.
요점은 싱글 스레드에선 메인스레드 종료시 프로세스가 종료되지만 멀티스레드 종료시 실행중인 스레드가 1개라도 있다면 프로세스는 종료되지 않는다. -> 기타 프로그램이 실행중일때 종료하려면 이 프로그램과 관련된 프로세스를 종료해야 가능하다 (백신 삭제할때 자주 나온다)
public static void main(String[] args){
//메인스레드는 요기서 main()을 뜻한다
}
작업 스레드
스레드를 구현하는 방식에는 2가지 방식있다.
1. Thread클래스로부터 직접생성
2. Theard를 상속받아 하위클래스 생성
스레드 클래스로부터 직접생성
먼저 스레드를 직접 생성했을때 스레드는 Thread-n이라는 형태의 이름으로 저장되며 이를 변경하려면 Thread.currentThread()메서드를 우선 선언해야하고 setName, getName 활용해 이름을 변경할수 있다.
//이름확인, 수정을 위한 선행코드
Thread thread = Thread.currentThread();
//이름변경
thread.setName("스레드 이름");
//이름확인(호출)
thread.getName();
하단의 코드는 터치했을때 소리와 동시에 텍스트를 출력하는 코드를 만들었지만 실행시 (A)가 전부 실행된뒤 (B)가 실행되는 순서로 예상과 다른 결과가 나타났다 (위에 말한 쓰레드는 한번에 1줄의 코드씩 실행하기에 (A)가 전부 실행되야 (B)가 실행되기 때문)
//양식 Thread a = new Thread (Runnable target);
public class BeepPrintEx1{
public static void main(String[] args) {
Toolkit toolkit = Toolkit.getDefaultToolkit;
for (int i=0; i<5; i++) {
toolkit.beep(); //1초마다 소리 출력 (A)
try{ Thread.sleep(1000); } catch (Exception e) {}
}
for (int i=0; i<5; i++) { //1초마다 텍스트 출력 (B)
System.out.println("띵")
try { Thread.sleep(1000); } catch(Exception e) {}
}
}
}
이를 해결하기 위해선 싱글쓰레드가 아닌 멀티쓰레드로 코드변경이 필요하고 이를 하단의 코드와 같이 작성한다면 문제없이 소리와 텍스트가 동시에 출력됨을 확인할수 있다.
(A) 코드 - 1초마다 사운드 출력
//소리출력 스레드 (A)
//Thread 직접생성
public class BeepThread extend Thread {
@Override
public void run() {
Toolkit toolkit = Toolkit.getDefaultToolkit;
for (int i=0; i<5; i++) {
toolkit.beep(); //1초마다 소리 출력 (A)
try{ Thread.sleep(1000); } catch (Exception e) {}
}
}
}
(B) 코드 - 1초마다 사운드 및 텍스트 출력 ((A)코드를 객체화하여 동시실행)
public class BeepPrintEx2 {
public static void main (String[] args) {
Thread thread = new BeepThread(); //(A)코드 객체화
thread.start(); //(A)코드 실행
for (int i=0; i<5; i++) { //1초마다 텍스트 출력 (B)
System.out.println("띵")
try { Thread.sleep(1000); }
catch(Exception e) {}
}
}
}
Theard를 상속받아 하위클래스 생성
1
스레드의 우선순위는
동기화메서드(synchronized)
OS에서 실행중인 하나의 애플리케이션을 프로세스라 칭하고멀티스레드는 1개의 프로세스가 여러개의 스레드를 갖는것이라 배웠다
멀티스레드로 작업할경우 여러 작업을 동시에 할수 있지만 여기에도 단점이 한가지 존재한다.
그것은 바로 객체를 공유해서 사용하는 경우이다.
객체의 공유
멀티스레드를 사용하는 프로그램은 스레드들이 객체를 공유해서 작업해야하는 경우가 있는데 같은객체를 공유하게되면 스레드A를 사용하던 객체가 스레드B에 의하여 다른결과가 나올수도 있다.
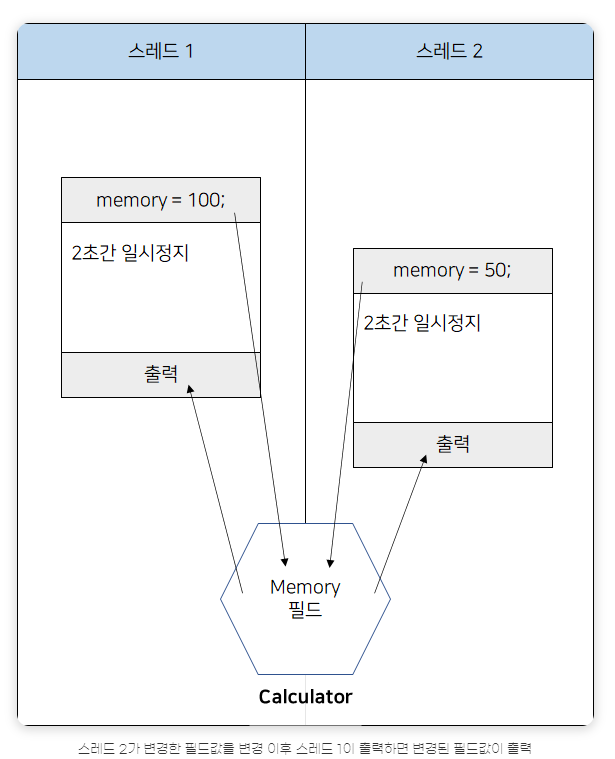
한가지 예시를 들자면 계산기 1개로 2명이 돌려쓰는경우가 있는데 내가 계산한 이전값(A)이 다른사람이(B) 써서 변경되는 사례로 이를 하단에 코드로 구현하였다..
// 메인코드
public class test1 {
public static void main(String[] args) {
Calculator calculator = new Calculator();
User1 user1 = new User1(); //User1 스레드 생성
user1.setCalculator(calculator); //공유객체 설정
user1.start(); //User1 스레드 시작
User2 user2 = new User2(); //User2 스레드 생성
user2.setCalculator(calculator); //공유객체 설정
user2.start(); //User2 스레드 시작
}
}
(A),(B) 코드 -> 이름, 저장값만 다름
public class User1 extends Thread { //(A)
private Calculator calculator;
public void setCalculator(Calculator calculator) {
this.setName("User1");
this.calculator = calculator;
}
public void run() {
calculator.setMemory(100) //메모리에 100 저장
}
################################
public class User2 extends Thread { //(B)
private Calculator calculator;
public void setCalculator(Calculator calculator) {
this.setName("User2");
this.calculator = calculator;
}
public void run() {
calculator.setMemory(50) //메모리에 50 저장
}
공유객체코드
//계산용 코드
public class Calculator{
private int memory;
public int getMemory() { //메모리 값 반환용
return memory;
}
public void setMemory(int Memory) { //초기 메서드
//public synchronized void setMemory(int Memory) { //동기화 메서드 synchronized추가
this.memory = memory;
try{
Thread.sleep(2000);
} catch(InterrupedException e) {}
System.out.println(Thread.currentThread().getName() + ": " + this.memory);
//Thread.currentThread().getName()는 스레드 이름이다.
}
}
현재 Calculator의 setMemory를 본다면 User1이 진행되고 User2가 진행되지만 User2가 User1과 같은객체를 참조하기에 User1과 User2는 같은결과가 나오는것을 확인할수 있다.
이러한 문제를 방지하기 위한게 동기화 메서드(synchronized)이다.
상단의 코드를 그림으로 표현하면 다음과 같다.
현재 코드가 어떤방식으로 진행되는지 나오는데 Calculator가 동일한 객체를 참조해서 사용하기 떄문에 User1도, User2도 50이 나타나는것이다.
이것을 현재 주석처리된 synchronized를 추가한다면 다음과 같은 그림이 된다.
Calculator에 synchronized를 추가하여 User1이 실행되는동안 User2가 실행되지 않도록 만든것이다,
요점정리
1. 프로세스(process) - OS에서 실행중인 하나의 애플리케이션 // 스레드(thread) - 1가지 작업을 실행하기 위하여 순차적으로 실행할 코드
2. 싱글 스레드에선 메인스레드 종료시 프로세스가 종료 / 멀티스레드 종료시 실행중인 스레드가 1개라도 있다면 프로세스는 종료되지 않는다. (백신을 끄려면 현재 켜져있는 익스플로러를 전부 닫아라)
3. 스레드의 우선순위를 정하는것을 스레드 스케쥴링이라 하며 우선순위방식 (1~10, 디폴트5) / 순환할당방식 (인터벌로 실행되며 우선순위는 JVM이 임의로 배정) 2가지이다.
4. 작업스레드를 구현하는 방식은 클래스를 직접생성, 쓰레드를 상속받아 하위클래스로 생성한다
5. synchronized는 객체를 동기화 시키는 기능으로 멀티스레드의 공유객체간 참조를 막아 비정상적인 출력을 막는것이 목적이다.