프로그램을 실행하면 JVM은 OS에 알맞도록 CPU에 프로세스를 할당해준다고 이야기하였다
그렇다면 어떤 방식으로 이 작업이 이뤄지는것일까?
CPU는 주소값을 통하여 메모리를 접근하는데 메모리공간을 효율적으로 사용하기위해 적용되는 개념인 바인딩에 관하여 설명하겠다.
주소공간
하단의 사진은 주소값이 어떤식으로 배열되어있는지 나타낸 사진으로 메모리의 주소공간은 0번지부터 시작하며 0번지 주소의 대응하는 명령어는 0100 1111임을 확인할수 있다 또한 메모리의 단위는 byte로 이뤄진다.
레지스터는 CPU가 계산할 데이터는 램에 쌓여있는데 이것들은 CPU 안에서 연산되어야하기에 CPU 내부에 임시로 값을 저장할 공간이 필요하고 이 공간을 뜻한다.
레지스터 크기에 따라 32비트, 64비트로 구분된다. (윈도우의 32(x84),64비트는 레지스터의 크기가 2^32 또는 2^64임을 의미한다.)

주소 바인딩 (메모리 할당과정)

링커 (Linker) - 컴파일러가 원시코드를 파일로 생성하면 이 파일에 라이브러리와 다른 파일들을 결합 (exe 같은 파일을 생성시킴
로더 (Loader) - 사용자 프로그램을 메모리에 적재시키는 프로그램 (지정 위치에서 시작해 메모리에 프로그램을 배치 -> 로딩을 해주는 역할)
프로그램이 실행을 위해 메모리에 적재되면(Symbolic Address) 그 프로세스를 위한 주소공간이 생성된다.
이것을 논리적 주소(logical address) 또는 가상 주소(vritual addres)라고 칭한다.
논리적 주소는 각 프로세스마다 독립적으로 0번지부터 시작되며(가상주소 이므로 "여기서부터 0이다" 라고 선언하면 거기가 0이 된다고 이해하면 된다) CPU는 이 논리적 주소를 바탕으로 명령을 실행한다.
그리고 이 논리적 주소(가상주소)를 새로운 물리적 주소(실제 하드웨어)로 주소를 할당시키는것(Mapping)을 주소바인딩이라 표현한다. (가상에 임의로 부여했던 주소를 실제 메모리에 할당하며 이 작업은 Mapping은 MMU라는 메모리 관리장치가 담당한다.)
요약하자면 CPU가 기계어 명령을 수행하기 위해선
1. 프로그램이 물리적 메모리에 올라가야한다. (가상이 아닌 실제 메모리상의 주소값을 가져야한다)
2. CPU가 기계어 명령을 수행하기 위해선 논리적 주소를 통해 메모리를 참고하며 논리적 주소가 물리적 메모리에 매핑되어야한다.
물리적 주소 (Physical Memory Address) -> 실제 메모리
실제 하드웨어에 올라가는 주소로 물리적 메모리의 낮은주소(메모리가 낮다 -> 접근이 더 빠르며 이것이 우선 실행된다) 크기가 굉장히 큰 배열을 갖는다 생각하면 되며 각 배열을 구분하는 인덱스 값을 갖는데 이 값을 물리적 주소라고 이야기한다. (메모리 자체의 인덱스 (0x0001, 0x0002)를 의미)
모든 프로세스는 논리적 주소가 0번지부터 시작해서 차례대로 증가하기에 물리적 주소도 시작주소만 다르지 연속적으로 배치되어있다. (OS는 메모리를 최대한 활용하기 위해서 0부터(낮고 가져오기 쉬운 순서부터) 시작하고 이를 연속적으로 배치한다)
논리적 주소 (Logical Memory Address) -> 가상 메모리
동일한 공간을 공유할때 서로 침범하지 않기 위해선 사람들이 자신의 공간을 벽으로 나눴듯이 컴퓨터에서도 자신의 공간을 표시한것이 논리적 주소라고 생각하면 된다. (이것은 Base Register, Limit Register를 활용해 물리적 주소를 정한다)
논리적 주소는 CPU 입장에서의 메모리 주소로 프로그램이 실행중에 CPU가 생성하는 주소이다. (CPU가 실행시 실제 메모리가 아닌 가상에 할당하기에 가상주소라고 이야기 하기도 한다.)
프로그램이 1MB라면 0x00000 ~ 0xfffff (2^20 -> 1M)이다.
모든 프로세스는 논리적 주소가 0번지부터 시작해서 차례대로 증가하기에 물리적 주소도 시작주소만 다르지 연속적으로 배치되어있다.
OS는 메모리를 최대한 활용하기 위해서 0부터(낮고 가져오기 쉬운 순서 -> 주로 기본적인 프로그램들) 배치를 시작하고 이를 연속적으로 배치한다.
Symbolic Address
프로그래머들이 특정 이름을 통해 변수를 지정하고 값을 저장할때 이 변수를 하드웨어 어디에 저장할지 정하지 않는데 이것을 변수의 이름을 통하여 그 값에 접근하는것이며 이 변수를 Symbolic Address라고 칭한다
이 주소가 컴파일되어 숫자 주소가 만들어지고 이것이 물리적인 메모리와 매핑되는것이다. -> int a = 5; 에서 a의 주소
(여담으로 심볼릭 링크라는것도 있는데 이는 윈도우의 바로가기 아이콘이라고 생각하면 된다)

주소를 확정하는 방식
컴퓨터에선 이를 Base Register에 Limit Register 를 더하여 주소를 확정한다.
또한 한 프로세스의 모든 논리적 주소에 동일한 Base Register를 더하는 주소할당을 "연속할당"이라고 표현한다.-> 연속적으로 나열된것 0x002가 끝인경우 다음 프로세스의 주소는 0x003이 되는것 (고정분할, 가변분할 2가지 방식이 있다)
불연속 할당
Base Register - 메모리(RAM)에 프로그램이 할당될때(논리적 주소) 프로그램의 시작주소를 의미한다. (재배치 레지스터라고 표현하기도 한다)
Limit Register - Base Register에서 현재 프로그램이 사용할수 있는 레지스터(논리적 주소)의 끝을 의미하며 CPU가 논리적 주소를 요청할 때 마다 한계 레지스터 값보다 작은 값인지를 검사 (논리적 주소에서 끝주소를 의미한다)
(Relocation Register와 Base Register는 동일한 것이라 생각하면 된다.)
Relocation Register - 접근할수 있는 물리적 메모리 주소의 최소(시작)값
조금 더 자세히 설명하면 상단 2개의 레지스터는 각 프로그램이 고유값으로 A프로세스의 논리적 주소는 Base Register + Limit Register로 Base Register가 0.00005이며 Limit Register가 10이면 A프로세스의 논리적 주소는 0.00005~0.00015까지 사용된다고 생각하면 된다.
만일 Limit Register가 10인데 주소를 0.00016까지 사용할경우 CPU는 trap(software interrupt)을 발생하고 프로그램을 에러를 뿜어내며 강제종료된다,
여기서 프로세스가 물리적 주소에 접근하려면 논리적 주소를 Mapping하는 과정이 필요한데 이것은 MMU(Memory Management Unit)가 이 역할을 수행한다.
주소 매핑 과정은 MMU가 하드웨어적으로 구현되어있으며 MMU는 논리적 주소에 Base Register값을 더해주면 된다.
프로세스(Process) - 컴퓨터 내에서 프로그램을 수행하는 컴퓨터에서 실행하는 하드웨어 유닛으로 1개 이상의 ALU 및 처리 레지스터 내장 (특정 목적을 수행하기 위해 메모리에 적재되어 프로세서에 의해 실행중인 프로그램(작업목록))
프로세서(Processor) -> 명령어를 해석하는 컴퓨터의 한부분으로 데이터 포맷을 변환하는 역할을 수행하는 프로세싱 시스템 (데이터 처리 시스템)을 의미하며 인쇄물을 출력하는 워드프로세서도 프로세서라 불리운다. (CPU, 어셈블러 등)
MMU기법 (MMU scheme)
MMU는 CPU가 논리적 주소를 참조하고 싶을때 그 주소값에 기준 레지스터값(base register)을 더해 물리적 주소값을 얻어낸다 (주소를 유추하고 싶을때는 MMU 논리적 주소에 base 레지스터값을 더해주면 된다)
기준레지스터(Relocation Register)는 재배치 레지스터라고 표현하기도 하며 프로세스의 물리적 메모리 시작주소(를 갖고있다.
MMU는 프로그램 주소공간이 연속적으로 적재되있음을 가정하에 진행한다.
멀티 프로세싱을 위해 가상주소를 사용한다.
논리적 주소를 물리적 주소로 매핑해주는 하드웨어 디바이스
CPU가 프로세스의 논리적주소와 기준 레지스터의 값을 더하여 물리적 주소 값을 얻는다 -> 이것은 곧 물리적 주소의 시작주소만 알아낸다면 주소변환이 가능하다는 의미이다.
마이크로 프로세서(microprocessor) - 기계어 코드를실행하기 위해 실행과정을 단계적으로 나누어 처리를 위한 마이크로 코드를 작성하고 이것을 단계적으로 처리하는 논리회로
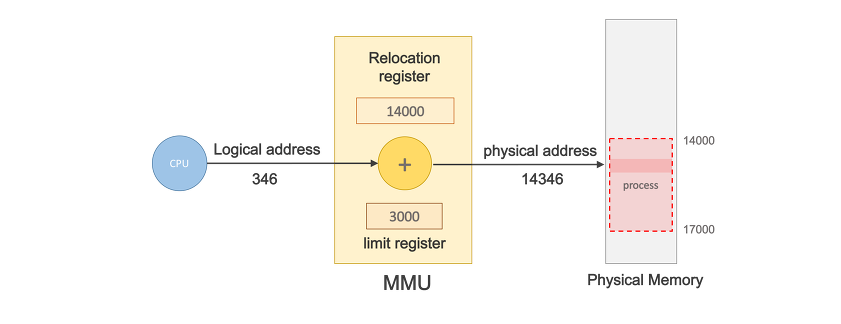
MMU scheme - 사용자 프로세스가 CPU에서 수행되며 생성해내는 모든 주소값에 대해 Base Register의 값을 더해준다.
user program - Logical address만 다루며 실제 물리적 주소를 볼수 없다.
주소의 매핑은
Relocation Register과 base Register는 같은 것으로 생각하면 된다?
(주소 매핑 과정은 빈번하게 이뤄지므로 MMU는 하드웨어적으로 구성되어있다)

여기서 굳이 Mapping하지말고 물리적 주소만 쓰면 속도가 더 빠르지 않냐는 궁금증이 생기는데 만일 논리적 주소를 사용하지 않고 물리적 주소 그러니까 실제 HW의 주소만 사용하면 같은 프로그램이 존재할때 한개의 프로그램은 실행되지 않는다 (크롬 여러창을 띄울수 없다고 생각하면 된다 -> 게임 클라이언트가 실행중인데 또 실행하면 이미 실행중이기에 다른 클라이언트가 안켜진다)
반면 논리적 주소는 컴파일할때 주소가 확정되는것이 아닌 실제 프로그램을 실행시킬때 메모리 빈공간에 논리적 주소(가상주소)를 만들고 물리적 주소와 같이 바인딩 하기에 물리적 주소가 같은 프로그램을 여러개 띄울수 있는것이다.
여기서 바인딩은 어느시점에서 논리적주소(가상주소)가 물리적주소(실제주소)로 언제 Mapping할것이가? 궁금증이 생길것이다.
바인딩의 방식은 물리적 메모리의 주소가 결정되는 시점에 따라 컴파일 타임 바인딩,로드 타임 바인딩, 실행시간 바인딩 3종류로 구분된다.

컴파일 타임 바인딩(Compile time binding)
프로그램을 컴파일할때 물리적 메모리 주소가 결정되는 방식 (프로그램 전체가 메모리에 올라가야한다)
즉, 처음부터 프로그램 내부에서 사용하는 주소(논리적 주소)와 물리적 메모리 주소가 동일
물리적 메모리 위치 변경을 하려면 재컴파일을 사용하며 기점유 하고있는 프로세스가 있는경우도 있다.
하나의 프로세스만 사용할때 사용하며 현재 범용적으로 사용중인 멀티 프로세싱에 부적합한 로드방법이다.
(이미 실제 메모리에 사용중인 크롬A의 주소가 있는데 크롬B를 그 사이에 호출하고 주소를 넣을순 없다 -> 우리는 앞서 메모리는 연속적으로 나열된다고 했는데 컴파일 타임 바인딩은 실행시점만 주소에 값을 넣을수 있기에 추가적인 실행은 불가능하다.)
로드 타임 바인딩(Load time binding)
프로그램 시작시(메모리에 로드,적재될때) 물리적 메모리 주소가 결정되며 로더의 책임하에 물리적 메모리 주소가 부여되며 프로그램이 종료될 때까지 물리적 메모리상의 위치 고정
초기에 부여되는 논리적 주소와 물리적 주소가 다르기때문에 멀티 프로세싱 환경에 용이하다 (물리적 메모리 주소와 논리적 메모리 주소를 분리하여 처음엔 가상주소로 들고있다가 프로그램 실행시 물리적 주소로 변경, 프로그램 종료전까지 물리적 메모리상의 위치가 고정)
프로그램 내부에서 사용하는 주소(논리적 주소)와 물리적 메모리 주소는 다른방식이다.
메모리를 참조하는 명령어를 다 변경해야하는 단점으로 메모리 로딩시간이 엄청 오래걸리는 단점으로 잘 사용되진 않는다.
실행시간 바인딩 (execution time binding 또는 run time binding)
프로그램 실행 이후로 프로그램이 위치한 물리적 메모리상의 주소의 변경이 가능한 바인딩방식 (실시간 물리적 주소의 변경을 의미하며 이것은 프로세스가 메모리에 연속적(Continuous)으로 적재된것을 가정하에 진행한다)
CPU가 주소를 참조할때마다 해당 데이터의 물리적 메모리가 어디에 있어야하는지 주소매핑테이블(address mapping table)을 통해 바인딩을 점검한다.
실행시간에 바인딩이 이뤄지기에 기준 레지스터(Base Register)와 한계 레지스터(Limit Register)를 포함한 MMU라는 하드웨어적인 자원이 필요하다
동적적재 (Dynamic Loading)
디스크에 프로그램을 여러 루틴(Function)으로 나눠 저장
해당 루틴이 실제 호출되기 전까지는 루틴을 메모리에 미적재, 메인 프로그램만 메모리에 적재하여 수행
루틴이 호출되면 바인딩 수행
미사용할 루틴은 메모리에 미적재하여 메모리의 효율적 사용이 가능
요약
1. 프로세스는 논리적 주소(가상주소)에 배치된다.
2. 논리적 주소를 물리적 주소(실제 하드웨어 주소)로 변환하는걸 바인딩이라 한다
3. 바인딩은 Base Register + Limit Register를 통해 주소값을 확정짓는다.
'CS' 카테고리의 다른 글
| 운영체제란 (0) | 2023.03.30 |
|---|---|
| 프로세서, 프로세스 (0) | 2023.03.21 |
| 제네릭(Generic) (0) | 2023.03.14 |
| 객체 지향 프로그래밍 (OOP) - 2 (5대원칙) (0) | 2023.03.02 |
| 스택트레이스(Stack Trace) (0) | 2023.02.26 |



